Bayesian Optimization for Chemical Hyperparameter Tuning: A Machine Learning Framework for Accelerated Drug Discovery
This article provides a comprehensive guide to Bayesian Optimization (BO), a powerful machine learning strategy for efficiently tuning hyperparameters in chemical and drug discovery applications.
Bayesian Optimization for Chemical Hyperparameter Tuning: A Machine Learning Framework for Accelerated Drug Discovery
Abstract
This article provides a comprehensive guide to Bayesian Optimization (BO), a powerful machine learning strategy for efficiently tuning hyperparameters in chemical and drug discovery applications. Tailored for researchers and drug development professionals, it covers the foundational principles of BO, including surrogate models and acquisition functions. The content explores methodological implementations for optimizing reaction parameters, molecular properties, and pharmaceutical formulations, alongside advanced techniques for troubleshooting noisy, multi-objective problems. Finally, it presents rigorous validation strategies and comparative performance analyses against traditional optimization methods, demonstrating BO's capacity to reduce experimental costs and accelerate the development of new therapeutics.
Beyond Trial and Error: Foundational Principles of Bayesian Optimization
Frequently Asked Questions (FAQs)
Q1: What are the main limitations of traditional One-Factor-At-a-Time (OFAT) optimization that Bayesian optimization addresses?
OFAT approaches explore only a limited subset of fixed combinations in the reaction space and often miss important regions of the chemical landscape, especially as additional reaction parameters multiplicatively expand the space of possible experimental configurations [1]. Bayesian optimization addresses this by using machine learning to balance exploration of new materials with exploitation of existing knowledge, guiding the search toward optimal materials with far greater efficiency [2] [1].
Q2: How can I handle categorical variables like solvents and catalysts in Bayesian optimization?
Categorical variables can be represented by converting molecular entities into numerical descriptors [1]. In one pharmaceutical optimization study, researchers successfully handled parameters including solvent (11 options), iodine source (5 options), and catalyst (3 options) by representing the reaction condition space as a discrete combinatorial set of potential conditions [3]. The platform automatically filtered impractical conditions like unsafe combinations or temperatures exceeding solvent boiling points [1].
Q3: My optimization is stuck in local optima. What advanced BO techniques can help?
Several advanced approaches address this challenge:
- Feature Adaptive BO (FABO): Dynamically adapts material representations throughout optimization cycles [2]
- Reasoning BO: Leverages LLMs' inference abilities to generate scientific hypotheses and avoid local optima [4]
- Multi-task BO: Transfers knowledge from previous optimization campaigns to accelerate new ones [5]
- Parallel Bayesian Optimization: Uses scalable acquisition functions like q-NParEgo and TS-HVI for highly parallel HTE applications [1]
Q4: How much experimental data do I need to start benefiting from Bayesian optimization?
Bayesian optimization is particularly valuable in the small-data regime. For novel tasks, you can start with algorithmic quasi-random Sobol sampling to select initial experiments that diversely cover the reaction space [1]. For related tasks, multi-task Bayesian optimization can leverage data from previous campaigns—one study successfully used 96 data points from auxiliary tasks to significantly accelerate optimization of new reactions [5].
Troubleshooting Guides
Issue 1: Poor Performance in High-Dimensional Search Spaces
Symptoms:
- Slow convergence despite many experiments
- Algorithm fails to identify promising regions of chemical space
- Inconsistent performance across similar substrates
Solutions:
- Implement Feature Adaptive Bayesian Optimization (FABO) which automatically identifies the most relevant molecular features during optimization [2]
- Use maximum relevancy minimum redundancy (mRMR) or Spearman ranking for feature selection to reduce dimensionality [2]
- Start with a complete feature set including both chemical and geometric characteristics, then allow the algorithm to adapt representations [2]
- For reaction optimization with many categorical variables, employ a discrete combinatorial representation with constraint checking [1]
Validation: In MOF discovery tasks, FABO effectively reduced feature space dimensionality and accelerated identification of top-performing materials across CO₂ adsorption and band gap optimization tasks [2].
Issue 2: Inefficient Optimization of Multiple Objectives
Symptoms:
- Conditions that improve yield reduce selectivity
- Difficulty balancing economic, environmental, and performance objectives
- Inability to identify Pareto-optimal conditions
Solutions:
- Implement scalable multi-objective acquisition functions like q-NParEgo, Thompson sampling with hypervolume improvement (TS-HVI), or q-Noisy Expected Hypervolume Improvement (q-NEHVI) for large batch sizes [1]
- Use the hypervolume metric to quantify performance in multi-objective space, considering both convergence toward optimal objectives and diversity [1]
- For pharmaceutical applications, simultaneously optimize yield, selectivity, and process safety considerations [1]
Case Study: In pharmaceutical process development, a multi-objective approach successfully identified multiple reaction conditions achieving >95 area percent yield AND selectivity for both Ni-catalyzed Suzuki coupling and Pd-catalyzed Buchwald-Hartwig reactions [1].
Issue 3: Transferring Knowledge Between Related Optimization Tasks
Symptoms:
- Repeatedly starting from scratch for similar reactions
- Inability to leverage historical optimization data
- Wasted resources on preliminary exploration
Solutions:
- Implement Multi-Task Bayesian Optimization (MTBO) using multitask Gaussian processes that learn correlations between different tasks [5]
- For medicinal chemistry applications, leverage data from previous C–H activation optimizations to accelerate new substrate optimization [5]
- When multiple auxiliary tasks are available, MTBO performance improves significantly—one study showed optimal conditions found in fewer than five experiments when using four auxiliary tasks [5]
Performance Data: In experimental C–H activation reactions with pharmaceutical intermediates, MTBO demonstrated large potential cost reductions compared to industry-standard process optimization techniques [5].
Experimental Protocols & Methodologies
Protocol 1: Feature Adaptive Bayesian Optimization (FABO) for Materials Discovery
Application: Discovering high-performing metal-organic frameworks (MOFs) for specific applications [2]
Workflow:
- Initialization: Begin with a complete, high-dimensional representation of each material (chemical + pore geometric characteristics)
- Feature Representation:
- Represent chemistry using Revised Autocorrelation Calculations (RACs)
- Include stoichiometric feature sets
- Compute RACs over the crystal graph of the material
- Adaptive Cycle (repeated each BO cycle):
- Perform feature selection using mRMR or Spearman ranking
- Select 5-40 features based on the specific task
- Update surrogate model with selected features
- Select next experiment using acquisition function (EI or UCB)
Materials: QMOF database (8,437 materials with DFT-calculated band gaps) or CoRE-2019 database (9,525 materials with gas adsorption data) [2]
Table 1: FABO Performance Across MOF Optimization Tasks
| Target Property | Database | Key Influencing Factors | FABO Performance |
|---|---|---|---|
| CO₂ Adsorption (16 bar) | CoRE-2019 | Primarily pore geometry | Outperformed fixed representations |
| CO₂ Adsorption (0.15 bar) | CoRE-2019 | Geometry + chemistry | Identified expert-aligned features |
| Electronic Band Gap | QMOF | Material chemistry | Efficient high-dimensional optimization |
Protocol 2: Highly Parallel Multi-Objective Reaction Optimization
Application: Pharmaceutical reaction optimization with 96-well HTE platforms [1]
Workflow:
- Experimental Design:
- Define reaction condition space as discrete combinatorial set
- Include categorical (solvent, catalyst, ligand) and continuous parameters (temperature, concentration)
- Implement constraint checking for impractical conditions
- Initial Sampling: Use Sobol sampling for initial batch to maximize reaction space coverage
- Optimization Cycle:
- Train Gaussian Process regressor on experimental data
- Use scalable acquisition function (q-NParEgo, TS-HVI, or q-NEHVI)
- Select batch of experiments balancing exploration and exploitation
- Run experiments using automated platform
- Update model and repeat for desired iterations
Validation: In nickel-catalyzed Suzuki reaction optimization (88,000 possible conditions), this approach identified conditions with 76% yield and 92% selectivity where traditional HTE plates failed [1].
Protocol 3: Multi-Task Bayesian Optimization for Medicinal Chemistry
Application: Accelerating optimization of precious intermediate reactions in drug discovery [5]
Workflow:
- Data Preparation:
- Collect historical optimization data from related reactions
- Align parameter spaces across different substrates
- Model Setup:
- Replace standard Gaussian Process with multitask GP
- Model learns correlations between different reaction tasks
- Optimization Execution:
- Leverage auxiliary task data (typically 96 data points)
- Multitask GP uses covariance between tasks to improve predictions
- Balance exploration with knowledge transfer from similar reactions
Case Study Results: For Suzuki couplings, MTBO achieved better and faster results than single-task BO when auxiliary tasks had similar reactivity, determining optimal conditions in fewer than five experiments when using multiple auxiliary tasks [5].
Research Reagent Solutions
Table 2: Essential Components for Bayesian Optimization Workflows
| Reagent/Component | Function | Application Example |
|---|---|---|
| Gaussian Process Regressor | Probabilistic surrogate model for predicting reaction outcomes with uncertainty quantification | Core model in FABO for MOF discovery [2] |
| mRMR Feature Selection | Maximum Relevancy Minimum Redundancy feature selection to balance relevance and redundancy | Dimensionality reduction in molecular representation [2] |
| Sobol Sequences | Quasi-random sampling for initial space-filling experimental design | Initial batch selection in parallel optimization [1] |
| Multi-task Gaussian Processes | Transfer learning between related optimization tasks | Leveraging historical C–H activation data for new substrates [5] |
| Scalable Acquisition Functions (q-NParEgo, TS-HVI) | Guide batch experiment selection in multi-objective optimization | 96-well plate optimization in pharmaceutical development [1] |
| Knowledge Graphs | Structured storage of domain knowledge and experimental results | Reasoning BO framework for storing chemical insights [4] |
Workflow Visualization
Bayesian Optimization Core Cycle
Feature Adaptive BO (FABO) Workflow
Multi-Task Bayesian Optimization Framework
Core Components of the Bayesian Optimization Framework
Frequently Asked Questions (FAQs)
1. What are the two essential components of the Bayesian Optimization framework? The Bayesian Optimization (BO) framework consists of two core components: a probabilistic surrogate model used to emulate the expensive objective function, and an acquisition function that guides the selection of the next point to evaluate by balancing exploration and exploitation [6] [7] [8]. The surrogate model, often a Gaussian Process (GP), provides a posterior distribution of the function, while the acquisition function uses this information to decide where to sample next [9] [10].
2. Why is a Gaussian Process commonly chosen as the surrogate model? Gaussian Processes (GPs) are a common choice for the surrogate model because they are flexible, non-parametric models that provide not only a mean prediction for the objective function at any point but also a measure of uncertainty (variance) around that prediction [8] [11]. This uncertainty quantification is essential for the acquisition function to effectively balance exploring regions with high uncertainty and exploiting regions with promising mean predictions [9] [6].
3. What is the difference between the Probability of Improvement (PI) and Expected Improvement (EI) acquisition functions?
The Probability of Improvement (PI) acquisition function selects the next point based on the highest probability of achieving any improvement over the current best observation [9] [11]. In contrast, the Expected Improvement (EI) acquisition function considers both the probability of improvement and the magnitude of that potential improvement, making it a popular and often more effective choice [9] [6] [10]. EI is defined as EI(x) = E[max(f(x) - f(x*), 0)], where f(x*) is the current best value [6].
4. My optimization seems stuck in a local minimum. How can I encourage more exploration? This is a classic sign of overexploitation. You can address this by:
- Adjusting the acquisition function: If using Upper Confidence Bound (UCB), increase the
κparameter to weight the uncertainty term more heavily, encouraging exploration [8] [11]. If using Probability of Improvement (PI), increasing theεparameter can force the algorithm to look beyond the immediate vicinity of the current best point [9]. - Using "plus" acquisition functions: Some software implementations offer acquisition functions like
'expected-improvement-plus'that automatically detect overexploitation and modify the model to encourage exploration [10].
5. Why does the optimization become slow as the number of trials increases, and what can I do?
The computational cost of refitting the Gaussian Process surrogate model grows cubically (O(n³)) with the number of observations n [12]. For high-dimensional problems or long runs, consider:
- Using a different surrogate model like Random Forests, which can be more scalable for certain problems [12] [11].
- Leveraging parallel Bayesian Optimization algorithms that can suggest multiple points to evaluate simultaneously, thus making better use of computational resources [13] [10].
Troubleshooting Common Experimental Issues
Issue 1: Poor Convergence or Unphysical Suggestions in Chemical Design
Problem: The algorithm fails to find good candidates or suggests parameter combinations that are chemically impossible or unstable [12].
Diagnosis and Solution:
| Diagnostic Step | Solution |
|---|---|
| Check the feasibility of the suggested points against known chemical rules. | Incorporate hard constraints into the BO algorithm to explicitly rule out invalid regions of the search space [12]. |
| Analyze if the problem has a highly discontinuous or complex search space that a standard GP with a smooth kernel cannot model well. | Use a Random Forest surrogate model, which can handle discontinuities more effectively and can be integrated with domain knowledge [12]. |
| Verify the initial dataset. A poorly chosen initial set of points can lead the model to form incorrect beliefs about the objective function. | Use space-filling designs like Latin Hypercube Sampling for the initial points to ensure the space is well-covered from the start [8]. |
Issue 2: Handling Noisy or Failed Experimental Evaluations
Problem: In real-world chemistry experiments, evaluations can be noisy, or a suggested experiment might fail to return a valid result (e.g., a failed synthesis) [7] [10].
Diagnosis and Solution:
| Diagnostic Step | Solution |
|---|---|
| Determine if the objective function is stochastic (noisy) or if some evaluations result in errors. | For noisy measurements, ensure your GP model includes a Gaussian noise term (likelihood) during fitting, which is a standard feature in most GP implementations [11] [10]. |
| If experiments occasionally fail, the data contains "objective function errors." | Use a BO algorithm that can handle such errors. For instance, the bayesopt function in MATLAB can model the probability of constraint satisfaction and integrate it into the acquisition function [10]. |
Issue 3: Performance and Scalability in High-Dimensional Spaces
Problem: The optimization is prohibitively slow, or performance degrades when tuning a large number of hyperparameters (e.g., >20) [12].
Diagnosis and Solution:
| Diagnostic Step | Solution |
|---|---|
| Assess the dimensionality of your search space. Standard BO with GP is known to struggle in high-dimensional spaces (>20 dimensions) [12]. | Consider using a scalable surrogate model like a Random Forest or employing dimensionality reduction techniques before optimization [12]. |
| Evaluate if all parameters are equally important. | Perform a sensitivity analysis to identify less influential parameters and fix them to reasonable values, thereby reducing the effective dimensionality of the problem [14]. |
Bayesian Optimization Workflow
The following diagram illustrates the iterative cycle of the Bayesian Optimization framework.
Research Reagent Solutions
The following table details the essential "research reagents" or core components needed to implement a Bayesian Optimization experiment in chemical tuning.
| Item | Function & Application |
|---|---|
| Gaussian Process (GP) | The core surrogate model. It uses a prior distribution over functions and updates it with data to produce a posterior that predicts the objective and quantifies uncertainty [9] [6] [11]. |
| Expected Improvement (EI) | A widely used acquisition function. It suggests the next experiment by calculating the expected value of improvement over the current best result, naturally balancing exploration and exploitation [6] [10]. |
| ARD Matérn 5/2 Kernel | A common covariance function for the GP. It defines how the objective function values at different points are correlated, and Automatic Relevance Determination (ARD) helps handle different input scales [10]. |
| Latin Hypercube Sampling | A method for selecting the initial set of experiments. It ensures good coverage of the entire parameter space with a minimal number of points, providing a solid starting point for the surrogate model [8]. |
| Software Library (e.g., Ax/BoTorch) | The experimental platform. These specialized libraries provide robust, tested implementations of the BO loop, including various models and acquisition functions, allowing researchers to focus on their domain problem [13] [6]. |
Troubleshooting Guides and FAQs
FAQ: Why is my Gaussian Process (GP) model providing poor predictions despite having a good mean prediction, and how can I improve it?
For reliability and safety assessments in drug development, the quality of the entire predictive distribution is crucial, not just the mean prediction. Poor uncertainty quantification often stems from non-robust estimation of the GP's hyperparameters. Standard methods like Maximum Likelihood Estimation (MLE) can sometimes produce inaccurate predictive distributions.
Solution: Implement a robust hyperparameter estimation algorithm that jointly optimizes for both data likelihood and the empirical coverage of the prediction intervals. This ensures the uncertainty bounds are reliable. A recent algorithm proposes maximizing the likelihood while also maximizing a Coverage Function (CF), which measures the accuracy of the prediction intervals, under the constraint that the model's predictive power (e.g., Q2 score) does not degrade [15].
FAQ: How can I perform Bayesian Optimization (BO) for a novel chemical task when I don't know the best molecular representation to use?
Choosing a fixed, high-dimensional molecular representation can lead to poor BO performance due to the curse of dimensionality. However, for novel optimization tasks, prior knowledge or large labeled datasets to select the best features are often unavailable [2].
Solution: Use a framework that integrates feature selection directly into the BO loop. One such method is Feature Adaptive Bayesian Optimization (FABO). It starts with a complete, high-dimensional feature set and dynamically refines it at each optimization cycle using efficient feature selection methods (like mRMR or Spearman ranking) on the data acquired during the campaign. This automatically identifies the most informative features for your specific task without requiring prior knowledge [2].
FAQ: My Bayesian Optimization gets stuck in local optima when tuning reaction parameters. How can I guide it towards better regions?
Traditional BO relies solely on the acquisition function and can lack the global, heuristic perspective needed to escape local optima. It also does not naturally incorporate domain knowledge, such as chemical reaction rules [4].
Solution: Integrate large language models (LLMs) with reasoning capabilities into the BO loop. In a Reasoning BO framework, an LLM can evaluate candidates proposed by the standard BO algorithm. Leveraging domain knowledge and historical data, the LLM generates scientific hypotheses and assigns confidence scores, helping to filter out implausible suggestions and guide the search toward more promising, globally optimal regions [4].
Detailed Experimental Protocols
Protocol 1: Hyperparameter Tuning with Feature Adaptive Bayesian Optimization (FABO)
This protocol is designed for optimizing chemical reactions or molecular properties when the optimal feature representation is unknown [2].
- Define Search Space: Start with a large, comprehensive set of numerical features (e.g., for molecules, this could include chemical descriptors RACs and geometric properties).
- Initial Sampling: Select an initial small set of experiments (e.g., 5-10 points) using a space-filling design like Latin Hypercube Sampling (LHS).
- Run Experiments: Execute the initial experiments (simulations or lab work) to obtain the target property values (e.g., reaction yield).
- FABO Loop: Iterate through the following cycle until a performance target or budget is met:
- Feature Selection: Using only the data collected so far, apply a feature selection method (e.g., Maximum Relevancy Minimum Redundancy - mRMR) to select the top
kmost relevant features for the current task. - Build Surrogate Model: Construct a Gaussian Process surrogate model using the adapted (reduced) feature set.
- Propose Next Experiment: Use an acquisition function (e.g., Expected Improvement - EI) on the surrogate model to select the most promising parameter set to test next.
- Run and Update: Run the proposed experiment and add the new {parameters, result} pair to the dataset.
- Feature Selection: Using only the data collected so far, apply a feature selection method (e.g., Maximum Relevancy Minimum Redundancy - mRMR) to select the top
Protocol 2: Robust Gaussian Process Surrogate Modeling for Reliability Analysis
This protocol ensures the GP model provides a reliable predictive distribution, which is critical for risk assessment and failure probability analysis in critical systems [15].
- Generate Learning Sample: Collect
ninput-output data points(Xs, Ys)from the expensive computational model (e.g., a pharmacokinetic simulation). - Standardize Data: Center and scale the output data
Ysto have a mean of zero and a standard deviation of one. - Define Kernel and Estimation Criteria: Select a kernel (e.g., Matérn 5/2) and define the two objectives for estimation:
- Likelihood: The standard log-likelihood of the data given the hyperparameters.
- Coverage Function (CF): A function that measures how well the 90% predictive intervals from the GP match the empirical coverage from the data.
- Estimate Hyperparameters: Instead of simple MLE, use a multi-objective optimization algorithm to find hyperparameters that jointly maximize the likelihood and the coverage function, while ensuring the model's Q2 predictivity coefficient remains above a acceptable threshold (e.g., 0.7).
- Validate Predictive Distribution: Rigorously validate the final GP model using various criteria beyond mean-error metrics, including the reliability of its prediction intervals across the input space.
Structured Data for Comparison
Table 1: Comparison of Key Hyperparameter Estimation Methods for Gaussian Processes
| Estimation Method | Key Principle | Advantages | Limitations | Best Suited For |
|---|---|---|---|---|
| Maximum Likelihood (MLE) | Finds parameters that make the observed data most probable [15]. | Conceptually straightforward, widely used, theoretical guarantees. | Can produce poor predictive distributions; sensitive to optimization [15]. | Initial modeling, cases where only mean prediction is needed. |
| Coverage-based Algorithm | Jointly maximizes likelihood and empirical accuracy of prediction intervals [15]. | Provides more reliable predictive uncertainty, robust for safety/reliability studies. | More computationally intensive than MLE. | Risk assessment, failure probability estimation, robust optimization. |
| Bayesian Approaches | Places a prior distribution on hyperparameters and computes the posterior [15]. | Accounts for uncertainty in hyperparameters, regularizes the solution. | High computational cost; requires expertise to define priors [15]. | Problems with limited data where prior knowledge is available and quantifiable. |
Table 2: Bayesian Optimization Frameworks for Chemical Synthesis
| Framework/Method | Core Innovation | Handles Novelty | Key Application in Chemistry | Reference |
|---|---|---|---|---|
| FABO | Dynamically adapts material/molecular representations during BO. | Excellent for novel tasks with no prior feature knowledge. | MOF discovery, organic molecule optimization. | [2] |
| Reasoning BO | Integrates LLMs for hypothesis generation and knowledge-guided search. | Uses domain knowledge to avoid local optima and implausible regions. | Chemical reaction yield optimization (e.g., Direct Arylation). | [4] |
| TSEMO | Uses Thompson sampling for efficient multi-objective optimization. | Requires a fixed parameter space. | Multi-objective optimization of nanomaterial synthesis and flow chemistry. | [16] |
The Scientist's Toolkit: Essential Research Reagents
Table 3: Key "Research Reagent Solutions" for Gaussian Process-based Bayesian Optimization
| Item / "Reagent" | Function / "Role in the Experiment" | Examples / "Specifications" |
|---|---|---|
| Surrogate Model | A cheap-to-evaluate statistical model that approximates the expensive computational or experimental process [17] [18]. | Gaussian Process (GP), Random Forest, Neural Networks. |
| Acquisition Function | A utility function that guides the selection of the next experiment by balancing exploration (high uncertainty) and exploitation (high promise) [16] [2]. | Expected Improvement (EI), Upper Confidence Bound (UCB). |
| Kernel / Covariance Function | The core component of a GP that defines the covariance between data points, thereby specifying the expected smoothness and patterns of the function being modeled [19]. | Matérn, Radial Basis Function (RBF). |
| Design of Experiments (DOE) | A systematic method for planning the initial set of experiments to efficiently sample the parameter space [18] [17]. | Latin Hypercube Sampling (LHS), Sobol sequence. |
| Feature Selection Method | Identifies the most relevant input features from a large pool, improving model interpretability and BO efficiency in high-dimensional spaces [2]. | mRMR (Maximum Relevancy Minimum Redundancy), Spearman ranking. |
Workflow and System Diagrams
FABO Workflow
Robust GP Estimation
Frequently Asked Questions
What is an acquisition function and why is it crucial in Bayesian Optimization?
An acquisition function is a decision-making tool that guides Bayesian Optimization (BO) by selecting the next experiment to evaluate. It uses the surrogate model's predictions (mean, μ) and uncertainty estimates (standard deviation, σ) to balance exploring new, uncertain regions of the search space against exploiting areas known to yield good results. This balance is vital for efficiently finding the global optimum of expensive black-box functions, such as chemical reaction yields, with a limited experimental budget [16] [20].
My BO algorithm seems stuck in a local optimum. How can I encourage more exploration? This common problem often stems from an over-exploitative acquisition function. Solutions include:
- Tuning the exploration parameter: For the Upper Confidence Bound (UCB) function
α(x) = μ(x) + λσ(x), increase the value ofλto give more weight to uncertain regions [21] [20]. - Switching the acquisition function: Consider using Expected Improvement (EI), which naturally balances the probability and magnitude of improvement. If you are using Probability of Improvement (PI), switching to EI is often recommended, as PI does not account for the magnitude of improvement and can be overly greedy [22] [20].
- Checking hyperparameters: An incorrectly tuned surrogate model, such as a Gaussian Process with a too-short lengthscale, can cause over-smoothing and premature convergence. Ensure your model's hyperparameters are properly specified [22] [23].
How do I choose the right acquisition function for my chemical optimization problem? The choice depends on your primary goal. The table below summarizes common functions and their typical use cases.
| Acquisition Function | Mathematical Formulation | Best For | Chemical Application Example |
|---|---|---|---|
| Probability of Improvement (PI) | PI(x) = Φ((μ(x) - f(x*)) / σ(x)) |
Quick, initial search for improvement; can get stuck in local optima [22]. | Initial screening of catalyst candidates. |
| Expected Improvement (EI) | EI(x) = (μ(x) - f(x*))Φ(Z) + σ(x)φ(Z) where Z = (μ(x) - f(x*)) / σ(x) |
A robust, general-purpose choice that balances the probability and size of improvement [22] [20]. | Optimizing reaction temperature and time for yield. |
| Upper Confidence Bound (UCB) | UCB(x) = μ(x) + λσ(x) |
Explicit control over exploration vs. exploitation via the λ parameter [21] [20]. |
High-risk screening of novel solvent combinations. |
| Thompson Sampling (TS) | Samples a function from the posterior surrogate model and maximizes it [16]. | Multi-objective optimization problems and scenarios favoring random exploration [16]. | Simultaneously optimizing for yield and E-factor (environmental impact) [16]. |
The optimization suggestions from my BO framework seem scientifically implausible. What could be wrong? This could indicate a problem with "hallucinated" suggestions, especially if you are using a language model-enhanced BO framework. Modern frameworks like "Reasoning BO" address this by incorporating domain knowledge. Ensure your setup includes:
- Confidence-based filtering: The framework should assign confidence scores to suggestions and filter out low-confidence, implausible ones [4].
- Knowledge integration: Use a dynamic knowledge management system that incorporates structured domain rules (e.g., chemical reaction rules) to keep suggestions scientifically grounded [4].
Troubleshooting Guides
Problem: Inconsistent or Poor Optimization Performance
Diagnosis: Poor performance can arise from an incorrect prior width in the surrogate model, over-smoothing, or inadequate maximization of the acquisition function itself [22].
Resolution:
- Verify Surrogate Model Hyperparameters: For a Gaussian Process, check the kernel amplitude (
σ) and lengthscale (ℓ). An inappropriate lengthscale can cause the model to over- or under-fit the data. Use marginal likelihood maximization or a validation set to tune these [22]. - Ensure Thorough AF Maximization: The acquisition function must be maximized effectively to find the best next experiment. Use a robust optimizer (e.g., L-BFGS-B or multi-start stochastic optimization) for this inner loop and avoid premature convergence [22].
- Implement a Hybrid Strategy: For chemical spaces with both continuous (temperature, concentration) and categorical (solvent, catalyst) variables, consider a hybrid approach. The TSEMO + DyOS framework has been successfully applied to complex chemical reactions, demonstrating precise control and efficient Pareto front development [16].
The following workflow diagram illustrates a robust Bayesian Optimization cycle that incorporates these troubleshooting principles.
Bayesian Optimization Troubleshooting Workflow
Problem: Optimizing for Multiple, Conflicting Objectives
Diagnosis: In chemical synthesis, you often need to optimize for multiple objectives simultaneously, such as maximizing yield while minimizing cost or environmental impact (E-factor). Standard BO for single objectives is insufficient.
Resolution: Adopt a Multi-Objective Bayesian Optimization (MOBO) framework.
- Define Pareto Front: The goal shifts from finding a single optimum to identifying a set of non-dominated solutions known as the Pareto front.
- Use Multi-Objective Acquisition Functions: Implement algorithms like Thompson Sampling Efficient Multi-Objective (TSEMO) or q-Noise Expected Hypervolume Improvement (q-NEHVI) [16].
- Experimental Protocol: A case study on optimizing a reaction for Space-Time Yield (STY) and E-factor used TSEMO. The surrogate model was constructed from initial data, and the acquisition function proposed new experiments until the Pareto frontier was developed after 68-78 iterations [16].
The logic of how an acquisition function like UCB balances exploration and exploitation for a single decision is shown below.
Acquisition Function Decision Logic
The Scientist's Toolkit: Research Reagent Solutions
The following table details key computational and experimental "reagents" essential for implementing Bayesian Optimization in chemical research.
| Tool / Reagent | Function / Explanation | Application Note |
|---|---|---|
| Gaussian Process (GP) | A probabilistic model that serves as the surrogate function, providing predictions and uncertainty estimates for unexplored reaction conditions [22] [16]. | The RBF kernel is common. Proper tuning of the lengthscale (ℓ) and amplitude (σ) is critical to avoid under/over-fitting [22]. |
| Expected Improvement (EI) | An acquisition function that selects the next experiment by considering the expected value of improvement over the current best result [20]. | A robust, general-purpose choice. Recommended over Probability of Improvement (PI) as it accounts for the magnitude of improvement [22]. |
| TSEMO Algorithm | A multi-objective acquisition function (Thompson Sampling Efficient Multi-Objective) used for optimizing several conflicting objectives at once [16]. | Successfully used for simultaneously optimizing chemical reaction yield and environmental E-factor [16]. |
| Knowledge Graph | A structured database of domain knowledge (e.g., chemical reaction rules) integrated into frameworks like "Reasoning BO" to keep optimization suggestions scientifically plausible [4]. | Helps prevent the LLM component from suggesting invalid or dangerous experiments, enhancing safety and trustworthiness [4]. |
| Summit Framework | A Python software toolkit specifically designed for chemical reaction optimization using BO and other self-optimization strategies [16]. | Provides implementations of various algorithms (including TSEMO) and benchmarks for comparing optimization strategies [16]. |
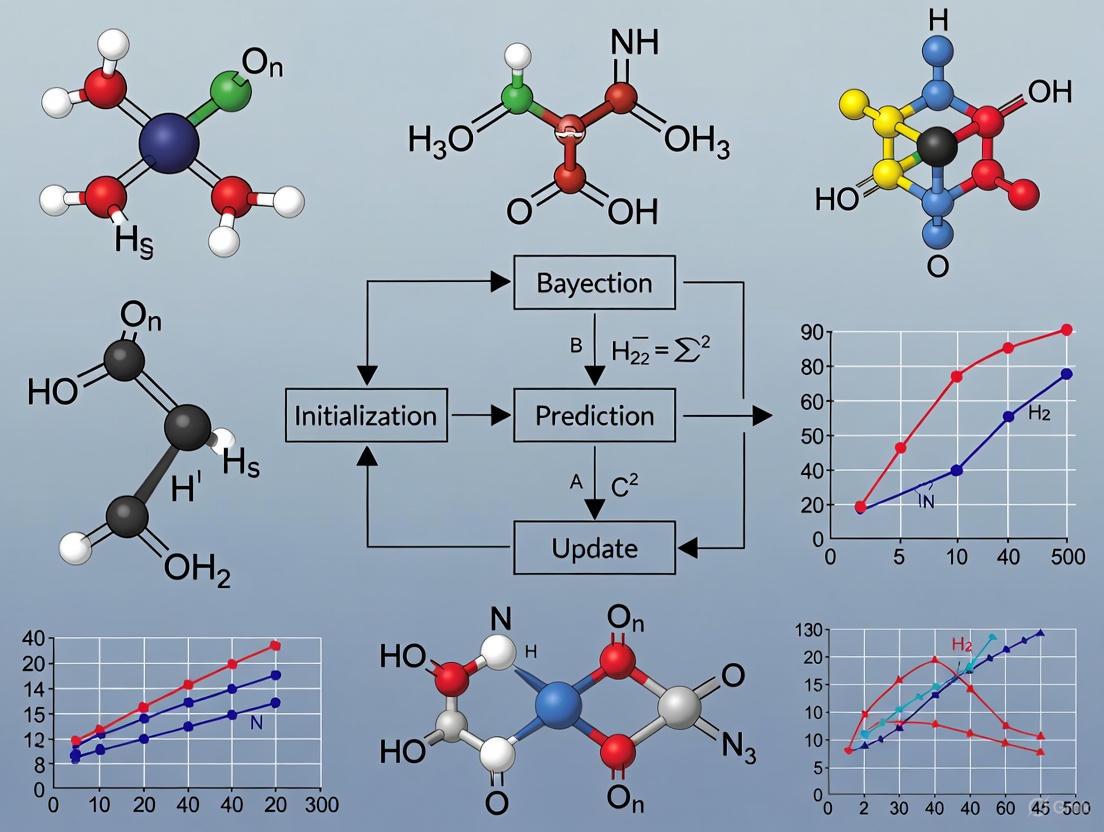
Bayesian Optimization (BO) is a powerful, sequential design strategy for globally optimizing expensive-to-evaluate black-box functions. This approach is particularly valuable in chemical synthesis and drug development, where experiments are costly and time-consuming, and the underlying functional relationships between variables and outcomes are complex and unknown [24] [16]. The core BO cycle operates by building a probabilistic surrogate model of the objective function and using an acquisition function to intelligently select the next experiment to perform, thereby balancing the exploration of unknown regions of the search space with the exploitation of known promising areas [9].
The sequential nature of this process—iteratively updating the model with new data and selecting new points—makes it exceptionally sample-efficient. This article details the step-by-step workflow of the sequential BO cycle, provides a real-world chemical application, and offers a technical support guide to address common implementation challenges faced by researchers.
The Step-by-Step Workflow
The Sequential Bayesian Optimization cycle consists of four key steps that are repeated until a stopping criterion is met, such as convergence or the exhaustion of an experimental budget. The workflow is illustrated in the diagram below.
Diagram 1: The Sequential Bayesian Optimization Cycle
- Step 1: Build/Update the Surrogate Model. The cycle begins with an initial, often small, dataset of performed experiments. A probabilistic surrogate model, most commonly a Gaussian Process (GP), is trained on this data. The GP models the unknown objective function by providing a posterior distribution—a mean prediction and an uncertainty estimate (variance) for every point in the search space [16] [9]. In the first cycle, this is the prior model; in subsequent cycles, it is updated with all available data.
- Step 2: Optimize the Acquisition Function. The surrogate model is used to construct an acquisition function, which guides the selection of the next experiment. This function quantifies the utility of evaluating any given point, balancing the goal of improving the model (exploring regions of high uncertainty) with the goal of finding the optimum (exploiting regions of high predicted performance). Common acquisition functions include Expected Improvement (EI), Probability of Improvement (PI), and Upper Confidence Bound (UCB) [24] [9].
- Step 3: Execute the New Experiment. The point that maximizes the acquisition function is selected as the next experiment to run. This is the key step where the algorithm interacts with the real world—for instance, by synthesizing a new catalyst or running a chemical reaction under the proposed conditions [25] [16].
- Step 4: Update the Dataset. The outcome of the new experiment (e.g., reaction yield) is measured and added to the growing dataset. The cycle then returns to Step 1, where the surrogate model is updated with this new data point. This closed-loop process continues, with each experiment intelligently informing the next, until the global optimum is located or the experimental budget is spent [25] [9].
Example Protocol: Optimizing an Organic Photoredox Catalyst
A study in Nature Chemistry provides a clear protocol for using sequential BO to discover and optimize organic molecular metallophotocatalysts for a decarboxylative cross-coupling reaction [25]. The following table summarizes the key reagents and their functions in this experiment.
Table 1: Research Reagent Solutions for Metallophotocatalysis
| Reagent | Function / Role in the Experiment |
|---|---|
| CNP-based OPCs (Cyanopyridine core) | Organic photoredox catalyst (PC) that absorbs light and facilitates single-electron transfer (SET) processes. |
| NiCl₂·glyme | Source of nickel, the transition-metal catalyst that operates in a synergistic cycle with the photocatalyst. |
| dtbbpy (4,4′-di-tert-butyl-2,2′-bipyridine) | Ligand that coordinates to the nickel center, modulating its reactivity and stability. |
| Cs₂CO₃ | Base, essential for facilitating the decarboxylation step in the reaction mechanism. |
| DMF solvent | Reaction medium. |
| Blue LED irradiation | Light source required to photoexcite the photoredox catalyst and initiate its catalytic cycle. |
Experimental Methodology
The research employed a two-step, sequential closed-loop BO workflow [25]:
Catalyst Discovery:
- Virtual Library: A virtual library of 560 synthesizable cyanopyridine (CNP) molecules was designed.
- Molecular Encoding: Each catalyst candidate was encoded using 16 molecular descriptors capturing key thermodynamic, optoelectronic, and excited-state properties.
- BO Setup: A batched Bayesian optimization was set up to maximize the reaction yield. The algorithm was initialized with 6 diverse candidates selected via the Kennard-Stone algorithm.
- Iterative Loop: The BO sequentially selected batches of 12 new catalysts to synthesize and test. After evaluating only 55 molecules (9.8% of the library), it identified a catalyst (CNP-129) achieving a 67% yield.
Reaction Condition Optimization:
- Expanded Search Space: The best-performing catalysts from the first step were used to optimize reaction conditions, varying the catalyst, nickel catalyst concentration, and ligand concentration—a space of 4,500 possible conditions.
- Second BO Loop: A second BO was run to navigate this multi-dimensional space.
- Result: After evaluating only 107 conditions (2.4% of the total space), the optimization discovered a set of conditions that delivered an 88% reaction yield, making it competitive with expensive iridium-based catalysts [25].
Troubleshooting Guide and FAQs
Q1: My BO convergence is slow or gets stuck in a local optimum. What can I do?
- Symptom: The algorithm fails to find significantly better results after several iterations.
- Possible Causes & Solutions:
- Inadequate Acquisition Function Tuning: The balance between exploration and exploitation is off. Solution: Adjust the parameters of your acquisition function. For example, increase the
ϵparameter in the Probability of Improvement (PI) function to force more exploration [9]. Consider switching to Expected Improvement (EI), which accounts for both the probability and magnitude of improvement [9]. - Poor Initial Sampling: The initial dataset is too small or not representative enough. Solution: Use space-filling designs like the Kennard-Stone algorithm or Latin Hypercube Sampling to select a better initial set of points [25].
- Suboptimal Representation: The features used to describe your chemicals or materials may not be relevant to the task. Solution: Implement adaptive representation techniques like FABO (Feature Adaptive Bayesian Optimization), which dynamically identifies the most informative molecular or material descriptors during the BO campaign [2].
- Inadequate Acquisition Function Tuning: The balance between exploration and exploitation is off. Solution: Adjust the parameters of your acquisition function. For example, increase the
Q2: The surrogate model performance is poor or training becomes computationally expensive.
- Symptom: Model predictions are inaccurate, or the time to update the model becomes prohibitive.
- Possible Causes & Solutions:
- High-Dimensional Search Space: Standard GP models scale cubically with the number of data points. Solution: For larger datasets (>1000 points), consider surrogate models with lower computational complexity, such as Random Forests or Bayesian neural networks [16].
- Noisy Data: Experimental noise can overwhelm the signal. Solution: Explicitly model noise in the GP by specifying a noise likelihood. Use acquisition functions that are robust to noise, such as the q-Noise Expected Hypervolume Improvement (q-NEHVI) for multi-objective problems [16].
Q3: How can I incorporate my domain knowledge or interpret the BO process?
- Symptom: The "black-box" nature of BO is a barrier to adoption and trust.
- Possible Causes & Solutions:
- Lack of Interpretability: Traditional BO provides limited insight into its decision-making. Solution: Integrate large language models (LLMs) into the loop. Frameworks like Reasoning BO use LLMs to generate and evolve scientific hypotheses, provide confidence scores for proposed experiments, and maintain a dynamic knowledge graph, making the optimization process more interpretable and trustworthy [4].
Q4: How do I handle both continuous and categorical variables (like catalyst types and solvents)?
- Symptom: The search space contains a mix of variable types.
- Possible Causes & Solutions:
- Standard Kernels are for Continuous Space: Common GP kernels (e.g., RBF) are designed for continuous inputs. Solution: Use specialized kernels that can handle categorical variables, such as the Hamming kernel, or one-hot encode categorical variables. Advanced BO platforms like Summit are specifically designed to handle such mixed-variable optimization common in chemical reactions [16].
Table 2: Common Acquisition Functions and Their Use Cases
| Acquisition Function | Key Principle | Best For |
|---|---|---|
| Probability of Improvement (PI) | Selects the point with the highest probability of being better than the current best. | Quick convergence when the optimum region is roughly known; can be sensitive to the ϵ parameter [9]. |
| Expected Improvement (EI) | Selects the point with the highest expected improvement over the current best. | The most widely used strategy; offers a good balance between exploration and exploitation [24] [9]. |
| Upper Confidence Bound (UCB) | Selects the point where the upper confidence bound (mean + κ * standard deviation) is highest. | Explicit control of the explore/exploit trade-off via the κ parameter [2] [24]. |
Table 3: Comparison of Optimization Methods in Chemical Synthesis
| Method | Key Advantage | Key Limitation |
|---|---|---|
| Trial-and-Error / OFAT | Simple to implement, intuitive. | Highly inefficient, ignores variable interactions, prone to missing global optimum [16]. |
| Design of Experiments (DoE) | Systematically accounts for variable interactions. | Requires relatively large initial data; efficiency drops with high dimensionality [16]. |
| Bayesian Optimization (BO) | Highly sample-efficient; ideal for expensive experiments. | Computational cost of model training; can be sensitive to initial data and hyperparameters [16]. |
Visualization of Acquisition Function Behavior
The following diagram illustrates how different acquisition functions make decisions based on the same surrogate model state, highlighting their exploration-exploitation trade-offs.
Diagram 2: Decision Logic of Different Acquisition Functions
From Theory to Lab Bench: Methodological Implementation and Drug Discovery Applications
Frequently Asked Questions (FAQs)
FAQ 1: My Bayesian Optimization seems to get stuck in a local optimum. How can I improve its global search? This is a common challenge, often related to the balance between exploration and exploitation. The acquisition function is key to managing this balance.
- Solution: Use acquisition functions that are more exploration-biased, especially in early optimization rounds. Upper Confidence Bound (UCB) explicitly handles this with a tunable parameter to control the exploration-exploitation trade-off [16] [26]. Alternatively, consider algorithms like Thompson Sampling Efficient Multi-Objective (TSEMO), which has demonstrated strong performance in navigating complex chemical spaces and avoiding local optima [16].
FAQ 2: How do I effectively include categorical variables, like solvent or catalyst type, in my continuous BO framework? Categorical variables require special handling as they have no natural order. Standard Gaussian Process kernels assume continuous, ordered inputs.
- Solution: Encode categorical variables using numerical descriptors. The optimization pipeline can represent the reaction condition space as a discrete combinatorial set, automatically filtering out impractical conditions (e.g., a reaction temperature above a solvent's boiling point) [1]. Another workaround for a limited number of candidates is to transform the problem into optimizing the composition of a mixture (e.g., a binary or ternary solvent mixture) [27].
FAQ 3: My experimental measurements are very noisy. Is BO still suitable? Yes, Bayesian Optimization is particularly well-suited for noisy environments. Its probabilistic nature allows it to model and account for uncertainty.
- Solution: Ensure your surrogate model is configured to handle noise. Gaussian Processes can use kernels that include a white noise term to explicitly model experimental noise [26]. For more complex, non-constant noise (heteroscedastic noise), specialized frameworks like BioKernel offer heteroscedastic noise modeling to improve accuracy [26].
FAQ 4: How many initial experiments are needed to start a BO campaign? There is no fixed number, but the initial dataset should be diverse enough to allow the surrogate model to build a preliminary map of the landscape.
- Solution: Use space-filling designs for your initial experiments. Methods like Sobol sampling or Latin Hypercube Sampling are designed to maximize the coverage of your parameter space with a relatively small number of points, increasing the likelihood of discovering promising regions [1] [28]. For instance, some successful chemical reaction optimizations have started with as few as 9 initial data points [29].
Troubleshooting Guides
Issue 1: Slow Optimization Convergence in High-Dimensional Spaces
Problem: The optimization takes too many iterations to find a good solution, especially when tuning more than just a few parameters (e.g., temperature, time, concentration, catalyst loading, solvent).
Diagnosis and Solutions:
- Diagnosis: The "curse of dimensionality" makes the search space exponentially larger. Traditional sequential BO methods may be too slow for practical use.
- Solution 1: Use Highly Parallel BO. Scale up by using large batch sizes. Frameworks like Minerva are specifically designed for high-throughput experimentation (HTE) and can handle batch sizes of 24, 48, or even 96 experiments at a time. This leverages automated platforms to explore the space much more rapidly [1].
- Solution 2: Choose Scalable Acquisition Functions. For multi-objective optimization in large batches, use acquisition functions that scale efficiently, such as:
- q-NParEgo
- Thompson Sampling with Hypervolume Improvement (TS-HVI)
- q-Noisy Expected Hypervolume Improvement (q-NEHVI) [1] These functions have better computational complexity for large parallel batches compared to alternatives.
Issue 2: Handling Multiple, Competing Objectives
Problem: You need to optimize for several objectives simultaneously (e.g., maximize yield AND minimize cost), but improving one objective often worsens another.
Diagnosis and Solutions:
- Diagnosis: Single-objective BO is not suitable; a multi-objective approach is required to find a set of optimal trade-offs (the Pareto front).
- Solution: Implement Multi-Objective Bayesian Optimization (MOBO). The goal is to maximize the hypervolume of the Pareto front, which measures both the quality and diversity of the solutions found [16] [1].
- Recommended Algorithms:
Issue 3: Translating BO Results to Practical, Scalable Processes
Problem: Optimal conditions found in small-scale, automated BO campaigns fail to perform well when scaled up to industrial production.
Diagnosis and Solutions:
- Diagnosis: The optimization did not account for scale-dependent variables or physical constraints of larger reactors.
- Solution 1: Incorporate Physical Constraints. Use physics-guided frameworks that integrate knowledge about the system (e.g., thermodynamics, mass transfer) into the BO process. For example, Gaussian Process Port-Hamiltonian Systems (GP-PHS) can embed physical laws as priors, leading to more physically realistic and scalable optimization results [30].
- Solution 2: Dynamic Optimization. For batch processes, optimize the entire parameter trajectory, not just fixed setpoints. BO has been successfully applied to dynamic optimization, for instance, to find optimal temperature and pressure profiles that minimize the total production cost in a pharmaceutical intermediate concentration process [29].
Experimental Protocol: A Standard BO Workflow for Reaction Optimization
The table below outlines a generalized, step-by-step protocol for implementing Bayesian Optimization, synthesizing methodologies from multiple case studies [16] [1] [31].
Table 1: Standard Experimental Protocol for a Bayesian Optimization Campaign
| Step | Procedure | Details & Technical Specifications |
|---|---|---|
| 1. Define Search Space | Identify parameters and their ranges. | Continuous: Temp. (25-95°C), Time (min-hr), Concentration (0.1-2.0 eq.). Categorical: Solvent (DMF, DMSO, MeOH, etc.), Catalyst (PSTA, AcOH, none) [31]. Apply constraints (e.g., T < solvent boiling point) [1]. |
| 2. Select BO Framework | Choose software and algorithmic components. | Frameworks: Summit, Minerva, BioKernel, JMP Pro [16] [26] [1]. Surrogate Model: Gaussian Process (Matern or RBF kernel) [26] [32]. Acquisition Function: For single-objective: UCB or EI. For multi-objective: TSEMO or q-NEHVI [16] [1]. |
| 3. Initial Sampling | Generate the first set of experiments. | Use Sobol sequences or Latin Hypercube Sampling to create a space-filling design for the initial batch (e.g., 8-16 experiments) [1] [28]. |
| 4. Run Experiments | Execute reactions and analyze outcomes. | Utilize automated platforms (e.g., robotic liquid handlers, flow reactors) or manual execution. Analyze yields/conversion via HPLC, GC, or inline spectroscopy (IR, NMR) [31] [27]. |
| 5. Update Model & Suggest Next | Input results into the BO loop. | The surrogate model is updated with new data. The acquisition function then suggests the next batch of experiments (single or parallel) with the highest expected improvement [16]. |
| 6. Iterate | Repeat steps 4 and 5. | Continue until convergence (e.g., no significant improvement over 2-3 iterations) or upon exhausting the experimental budget [16] [29]. |
Research Reagent Solutions
The following table lists key reagents and materials commonly used in BO-guided reaction optimization campaigns, along with their primary functions.
Table 2: Essential Reagents and Materials for Reaction Optimization
| Reagent/Material | Function in Optimization | Example from Literature |
|---|---|---|
| N-Iodosuccinimide (NIS) | Halogenating agent for functional group transformation. | Used as an iodinating agent in the optimization of terminal alkyne iodination [31]. |
| Polar Solvents (DMF, DMSO) | High-polarity solvents to dissolve reactants and influence reaction mechanism. | Commonly included in solvent screens for various reactions, including Suzuki couplings [1] [31]. |
| Non-Precious Metal Catalysts (Ni) | Earth-abundant, lower-cost alternative to precious metal catalysts like Pd. | A Ni-based catalyst was optimized in a Suzuki coupling reaction for pharmaceutical process development [1]. |
| Chloramine Salts | Oxidizing agent in halogenation reactions. | Used as an oxidant with an iodine salt in an alternative route for alkyne iodination [31]. |
| Tetralkylammonium Salts (e.g., TBAI) | Phase-transfer catalysts or iodide sources. | Listed as a potential iodine source in a multi-parameter optimization study [31]. |
Workflow Diagrams
Bayesian Optimization Core Loop
High-Throughput Experimentation (HTE) Integration
Technical Support Center
Troubleshooting Guides & FAQs
Q1: My Bayesian optimization loop is converging on candidates with high affinity but poor solubility. How can I adjust the process? A: This indicates an imbalance in your multi-objective function. The algorithm is prioritizing affinity. Implement a constrained optimization approach or adjust the weights in your objective function.
- Protocol: Setting Up a Weighted Sum Objective Function
- Define Normalized Objectives: Scale each property (e.g., pIC50 for affinity, LogS for solubility, pLD50 for toxicity) to a 0-1 range, where 1 is ideal.
- Assign Weights: Assign a weight (w) to each objective based on project priorities (e.g., waffinity=0.5, wsolubility=0.3, w_toxicity=0.2). Ensure weights sum to 1.
- Combine: Compute the total score for a molecule:
Score = (w_affinity * Norm_Affinity) + (w_solubility * Norm_Solubility) + (w_toxicity * Norm_Toxicity). - Optimize: Use this
Scoreas the single objective for your Bayesian optimizer to maximize.
Q2: The acquisition function in my Bayesian optimizer is not exploring the chemical space effectively and gets stuck. What can I do? A: This is often due to over-exploitation. The Upper Confidence Bound (UCB) acquisition function is tunable for this.
- Protocol: Tuning the UCB Acquisition Function
- Identify Parameter: The UCB function is
μ + κ * σ, whereμis the mean prediction,σis the uncertainty, andκis the tunable parameter. - Adjust κ: A low
κ(e.g., 0.1-1.0) favors exploitation (refining known good areas). A highκ(e.g., 5.0-10.0) favors exploration (probing high-uncertainty areas). - Implement a Schedule: Start with a high
κfor broad exploration and gradually decrease it over iterations to refine the best candidates.
- Identify Parameter: The UCB function is
Q3: How do I handle the computational cost of evaluating toxicity for every candidate in a large virtual library? A: Use a tiered filtering approach. Employ fast, cheap filters first before running expensive simulations.
- Protocol: Tiered Virtual Screening Workflow
- Step 1 - Rule-Based Filters: Apply hard filters (e.g., PAINS, REOS) to remove molecules with obvious structural alerts. This can eliminate 10-20% of the library.
- Step 2 - QSAR Models: Use pre-trained Quantitative Structure-Activity Relationship (QSAR) models for rapid toxicity (e.g., hERG, Ames) and solubility prediction.
- Step 3 - Multi-Objective Bayesian Optimization: Apply Bayesian optimization on the filtered library, using the predictions from Step 2 as objectives.
- Step 4 - Experimental Validation: Only the top-ranked candidates from the optimization require costly MD simulations or experimental assays.
Q4: My property predictions (e.g., LogS) have high uncertainty, which misleads the Bayesian model. How can I account for this? A: Bayesian optimization naturally handles uncertainty. You should ensure this predictive uncertainty is propagated correctly to the acquisition function.
- Checklist for Predictive Model Uncertainty:
- Model Calibration: Ensure your underlying machine learning models (e.g., for solubility) are well-calibrated. Use calibration plots.
- Use Probabilistic Models: Employ models that output a mean and variance (e.g., Gaussian Process models, Bayesian Neural Networks) rather than just a point estimate.
- Acquisition Function: Use an acquisition function like Expected Improvement (EI) or UCB that explicitly incorporates prediction uncertainty (
σ) to balance exploration and exploitation.
Data Presentation
Table 1: Comparison of Multi-Objective Optimization Strategies in Virtual Screening
| Strategy | Key Principle | Pros | Cons | Best for |
|---|---|---|---|---|
| Weighted Sum | Combines objectives into a single score. | Simple, fast, works with standard BO. | Sensitive to weight choice; may miss Pareto-optimal solutions. | Projects with clear, fixed priorities. |
| Constrained Optimization | Optimizes one objective subject to constraints on others. | Intuitive, mirrors experimental design. | Can be inefficient if feasible region is small. | Ensuring a candidate meets a minimum safety threshold. |
| Pareto Optimization | Seeks a set of non-dominated solutions (Pareto front). | Finds diverse trade-off options. | Computationally intensive; harder to analyze. | Exploratory phases where trade-offs are unknown. |
Table 2: Typical Ranges for Key Molecular Properties in Drug Discovery
| Property | Metric | Ideal Range | High-Risk Range |
|---|---|---|---|
| Affinity | pIC50 | >6.3 (nM) | <5.0 (nM) |
| Solubility | LogS | >-4.0 | <-6.0 |
| Toxicity (hERG) | pIC50 | <5.0 | >5.0 |
Experimental Protocols
Protocol: Standard Workflow for a Multi-Objective Bayesian Optimization Cycle
- Initialization: Select a small, diverse set of molecules (50-100) from the chemical space to form the initial training set.
- Property Evaluation: Calculate or predict the multi-objective properties (Affinity, Solubility, Toxicity) for the initial set.
- Model Training: Train a separate surrogate model (e.g., Gaussian Process) for each objective property using the initial data.
- Acquisition: Use a multi-objective acquisition function (e.g., Expected Hypervolume Improvement) to select the next most promising molecule(s) to "evaluate."
- Update: "Evaluate" the selected molecule(s) (i.e., get predictions from your oracle functions) and add the new data to the training set.
- Iteration: Repeat steps 3-5 for a predefined number of iterations or until convergence.
Mandatory Visualization
Title: Bayesian Optimization Workflow
Title: Tiered Screening Protocol
The Scientist's Toolkit
Table 3: Research Reagent Solutions for In Silico Multi-Objective Optimization
| Item | Function | Example Tools / Libraries |
|---|---|---|
| Cheminformatics Library | Handles molecular representation, fingerprinting, and basic descriptor calculation. | RDKit, OpenBabel |
| Descriptor Calculator | Generates quantitative numerical representations of molecular structures. | Mordred, PaDEL-Descriptor |
| Machine Learning Framework | Builds and trains surrogate models for property prediction. | scikit-learn, PyTorch, TensorFlow |
| Bayesian Optimization Library | Provides algorithms for efficient global optimization of black-box functions. | BoTorch, GPyOpt, Scikit-Optimize |
| Molecular Docking Software | Predicts binding affinity and pose of a ligand to a protein target. | AutoDock Vina, GOLD, Glide |
| ADMET Prediction Platform | Provides pre-trained or trainable models for solubility, toxicity, and other properties. | ADMETlab, OCHEM, proprietary software |
This technical support center provides troubleshooting guides and FAQs for researchers implementing Expert-Guided Multi-Objective Bayesian Optimization (MOBO) within the CheapVS framework for virtual screening, specifically on EGFR and DRD2 targets [33].
Frequently Asked Questions (FAQs)
FAQ: How does CheapVS incorporate human expertise into the optimization process? CheapVS uses a preferential multi-objective Bayesian optimization framework. It captures expert chemical intuition by having chemists provide pairwise comparisons of candidates, which guide the trade-offs between multiple drug properties like binding affinity, solubility, and toxicity. This feedback is translated into a latent utility function that the BO uses to prioritize subsequent screening candidates [33].
FAQ: My optimization is failing due to occasional errors from the docking model. How can I recover without restarting?
Bayesian optimization loops can be designed to recover from intermittent errors. If an evaluation fails, you can fix the issue (e.g., restarting a crashed service), and then restart the optimization from the last successful step using the data, model, and acquisition state stored in the optimization history. For stateful acquisition rules like TrustRegion, ensuring this state is correctly reloaded is crucial [34].
FAQ: Why might my Bayesian optimization perform poorly in molecule design? Common pitfalls in BO for molecule design include an incorrect prior width in the surrogate model, over-smoothing, and inadequate maximization of the acquisition function. Addressing these hyperparameter tuning issues is critical for achieving state-of-the-art performance [22].
FAQ: How can I handle experimental noise in my assay data during active learning? In noisy environments, a retest policy can be integrated into the batched Bayesian optimization process. This policy selectively chooses experiments to repeat based on their importance or uncertainty. To maintain a consistent experimental budget, each retest replaces one new candidate in a batch. This approach has been shown to help correctly identify more active compounds despite noise [35].
Troubleshooting Guides
Problem: Optimization process runs out of memory.
- Potential Cause: The search space may be too complex, or the surrogate model may be evaluating overly large datasets during acquisition function optimization [34] [36].
- Solutions:
- Simplify the Search Space: Reduce the number of parameters being optimized or decrease the complexity of their distributions [36].
- Batch Acquisition Evaluations: Configure your acquisition function optimizer to evaluate the acquisition function in smaller batches rather than on the entire candidate set at once [34].
- Increase Memory Allocation: If simplification is not possible, allocate more memory to the optimization job [36].
Problem: The algorithm appears to be exploring poorly and gets stuck in a local optimum.
- Potential Cause: Inadequate trade-off between exploration and exploitation, potentially due to a poorly tuned acquisition function or kernel hyperparameters [22] [35].
- Solutions:
- Check Hyperparameters: Review the width of the surrogate model's prior and the lengthscale of its kernel. An incorrectly set prior can hinder exploration [22].
- Adjust Acquisition Function: For noisy environments, consider using the Upper Confidence Bound (UCB) with a higher
βparameter to weight exploration more heavily [22] [35]. - Validate with a Retest Policy: In physically noisy assays, implement a retest policy to confirm promising candidates and prevent the algorithm from being misled by erroneous high readings [35].
Problem: Expert preferences do not seem to be guiding the search effectively.
- Potential Cause: The pairwise comparison data might be too sparse or inconsistent to learn a reliable utility function [33].
- Solutions:
- Increase Query Frequency: Present the expert with a slightly larger number of pairwise comparisons per optimization cycle to gather more preference data.
- Clarify Objectives: Ensure that the drug properties used for comparisons are well-defined and understood by the expert to maintain consistency in feedback.
Experimental Protocols
Protocol 1: Running the CheapVS Framework for EGFR/DRD2 This protocol outlines the core methodology for hit identification on EGFR and DRD2 targets as described in the CheapVS study [33].
- Library Preparation: Obtain a chemical library (e.g., 100,000 candidates). For initial setup, a small random subset (e.g., 5 initial points) is evaluated to seed the model [33] [34].
- Expert Preference Elicitation: Present the domain expert (medicinal chemist) with pairwise comparisons of candidate molecules. The expert chooses the preferred candidate based on the trade-off between multiple properties (e.g., binding affinity vs. solubility).
- Model Fitting: Fit a multi-output Gaussian process surrogate model to the available data, which includes both evaluated property vectors and the inferred preferences.
- Candidate Selection: Using a preferential MOBO acquisition function (which leverages the learned utility function), select the most promising batch of candidates for the next round of evaluation.
- Iterative Optimization: Repeat steps 2-4 for the desired number of optimization cycles or until a performance threshold is met.
- Hit Validation: The final output is a shortlist of top-ranking candidates. In the referenced study, this process identified 16/37 known EGFR drugs and 37/58 known DRD2 drugs after screening only 6% of the library [33].
Protocol 2: Implementing a Retest Policy for Noisy Assays This protocol mitigates the impact of experimental noise, common in biochemical assays [35].
- Define Batch Size: Set a fixed batch size (e.g., 100 compounds per batch [35]).
- Rank Candidates: Use your acquisition function to rank all unevaluated candidates.
- Identify Retest Candidates: Select a subset of the highest-value or most uncertain previously tested candidates for retesting. The number of retests (
n_retest) should be predefined. - Form Final Batch: The next batch consists of
n_retestretest candidates and(batch_size - n_retest)new candidates from the top of the ranking. - Update Model: Update the surrogate model with the new results, incorporating both new evaluations and retest data.
The following table summarizes key quantitative results from the CheapVS case study on EGFR and DRD2 targets, demonstrating its high efficiency [33].
Table 1: Summary of CheapVS Performance on EGFR and DRD2 Targets
| Metric | EGFR Target | DRD2 Target |
|---|---|---|
| Library Size | 100,000 compounds | 100,000 compounds |
| Screening Fraction | 6% | 6% |
| Known Drugs Recovered | 16 out of 37 | 37 out of 58 |
| Recovery Rate | 43.2% | 63.8% |
Research Reagent Solutions
Table 2: Key Resources for Implementing Expert-Guided MOBO
| Resource Name | Type | Function in the Experiment |
|---|---|---|
| Chemical Library | Data | A large collection (e.g., 100K candidates) of chemical compounds for virtual screening [33]. |
| Docking Model (e.g., AlphaFold3, Chai-1) | Software/Tool | Computationally measures the binding affinity between a ligand and the target protein (e.g., EGFR, DRD2) [33]. |
| Multi-output Gaussian Process | Surrogate Model | Models the multiple, correlated drug properties and learns the latent utility function from expert preferences [33] [37]. |
| Therapeutics Data Commons | Data Platform | Provides open-access, curated datasets and algorithms for benchmarking AI models across various stages of drug discovery [38]. |
Workflow and System Diagrams
CheapVS High-Level Workflow
Expert Preference Integration
Error Recovery Process
In the competitive landscape of pharmaceutical development, maximizing yield and quality in formulation and bioprocessing is paramount. Traditional optimization methods, such as one-factor-at-a-time (OFAT) approaches, are inefficient for complex, multi-parameter reactions and often fail to identify global optima due to their inability to account for factor interactions [16]. Bayesian Optimization (BO) has emerged as a powerful machine learning framework that transforms reaction engineering and bioprocess development by enabling efficient, cost-effective optimization of complex systems [16].
BO is a sample-efficient global optimization strategy that excels where evaluations are expensive and the search space is high-dimensional [13] [16]. It operates by constructing probabilistic surrogate models of the objective function (e.g., yield, purity) and using acquisition functions to intelligently guide the selection of subsequent experiments by balancing exploration of uncertain regions with exploitation of known promising areas [13]. This approach is particularly valuable in bioprocessing, where experiments are resource-intensive and the relationships between critical process parameters (CPPs) and critical quality attributes (CQAs) are often complex and non-linear.
The integration of BO into bioprocess development aligns with the industry's shift toward Quality by Design (QbD) and Process Analytical Technology (PAT), enabling data-driven, intelligent optimization of multi-parameter processes [39] [40]. With the global bioprocess optimization market projected for substantial growth, driven by demands for biopharmaceuticals and advanced therapies, adopting BO frameworks provides a strategic advantage in accelerating development while maintaining rigorous quality standards [40].
Essential Bayesian Optimization Frameworks and Tools
Implementing BO requires specialized software tools. The table below summarizes key Bayesian Optimization packages relevant to chemical and bioprocess applications.
Table 1: Selected Bayesian Optimization Software Packages
| Package Name | Core Models | Key Features | Applicability to Bioprocessing |
|---|---|---|---|
| BoTorch [13] | Gaussian Processes (GP), others | Multi-objective optimization, built on PyTorch | High - flexible for complex, multi-response problems |
| Ax/Dragonfly [13] | GP | Multi-fidelity optimization, modular framework | High - supports various experiment types and data sources |
| Summit [16] | GP (TSEMO algorithm) | Specialized for chemical reaction optimization, multi-objective | Very High - includes benchmarks and domain-specific features |
| COMBO [13] | GP | Multi-objective optimization | Medium - general-purpose but capable |
| Reasoning BO [4] | GP + Large Language Models (LLMs) | Incorporates scientific reasoning, knowledge graphs | Emerging - useful when leveraging domain knowledge |
The Feature Adaptive Bayesian Optimization (FABO) Framework
A significant challenge in applying BO to materials and molecules is selecting the appropriate numerical representation (feature set). The Feature Adaptive Bayesian Optimization (FABO) framework addresses this by dynamically identifying the most informative features during the optimization campaign [2]. FABO starts with a complete, high-dimensional representation of the material or molecule and, at each cycle, refines this representation using feature selection methods (e.g., mRMR, Spearman ranking) to retain only the most relevant features influencing performance [2]. This ensures the representation is both compact and informative, significantly enhancing BO efficiency, especially in novel tasks where prior knowledge is limited.
Frequently Asked Questions (FAQs) on Bayesian Optimization
Q1: My bioprocess has multiple critical quality attributes (CQAs) like yield and purity. How can Bayesian Optimization handle multiple, potentially competing, objectives?
Bayesian Optimization can effectively handle multi-objective problems through Multi-Objective Bayesian Optimization (MOBO). Instead of seeking a single optimal point, MOBO identifies a Pareto front—a set of solutions where improving one objective necessitates worsening another [16]. Frameworks like Summit implement algorithms such as the Thompson Sampling Efficient Multi-Objective (TSEMO) algorithm. This algorithm uses Gaussian Process models for each objective and an acquisition function that guides experiments toward populating the Pareto frontier, allowing you to make informed trade-off decisions based on your specific quality targets [16].
Q2: The initial experiments in my BO campaign are yielding poor results. Is the algorithm failing, and how can I improve its start?
It is common for BO to require a few cycles to model the complex response surface effectively. The performance is sensitive to the initial set of experiments, or "seed" data [4]. To ensure a robust start:
- Use Space-Filling Designs: Employ design of experiments (DoE) methods, such as Latin Hypercube Sampling, for the initial batch to ensure broad exploration of the search space [16].
- Incorporate Prior Knowledge: If available, use historical data or expert intuition to bias the initial sampling toward regions believed to be more promising. Emerging frameworks like Reasoning BO leverage Large Language Models (LLMs) to inject such domain priors directly, improving initial performance [4].
- Ensure Proper Feature Representation: If using FABO, starting with a comprehensive feature set is crucial, as a suboptimal initial representation can severely hinder finding the global optimum [2].
Q3: My experimental measurements are sometimes noisy. How robust is Bayesian Optimization to this noise?
BO, particularly when using Gaussian Process (GP) surrogates, is inherently capable of handling noisy observations. You can explicitly model the noise by specifying a likelihood function (e.g., a Gaussian likelihood) for the GP. The GP will then estimate the underlying function while accounting for the measurement uncertainty, preventing the algorithm from overfitting to noisy data points [13] [16]. The acquisition function will naturally balance the need to explore noisy regions to reduce uncertainty with the need to exploit confidently known optima.
Q4: I am optimizing categorical variables, like different cell culture media or resin types. Can Bayesian Optimization handle these alongside continuous parameters like temperature and pH?
Yes, this is a key strength of modern BO implementations. While GPs traditionally work with continuous inputs, kernels have been developed to handle mixed spaces containing both continuous and categorical parameters [16]. Software packages like BoTorch and Ax support these complex search spaces, allowing you to simultaneously optimize discrete choices (e.g., catalyst type, solvent) and continuous parameters (e.g., concentration, reaction time) within a single optimization campaign [13].
Troubleshooting Common Bayesian Optimization Workflow Issues
Problem: BO Algorithm Gets Stuck in a Local Optimum
- Symptoms: The algorithm repeatedly suggests experiments in a small region with only marginal improvement, failing to discover significantly better performance areas found in earlier screening.
- Possible Causes & Solutions:
- Cause 1: Overly Greedy Exploitation. The acquisition function's balance is skewed too heavily toward exploitation.
- Solution: Use an acquisition function like Upper Confidence Bound (UCB) and increase its
βparameter to weight uncertainty (exploration) more heavily [16]. Alternatively, use a portfolio of acquisition functions.
- Solution: Use an acquisition function like Upper Confidence Bound (UCB) and increase its
- Cause 2: Incorrect Kernel or Model Assumptions. The surrogate model's kernel cannot capture the complexity of the true response surface.
- Solution: Validate the GP model's predictions on a hold-out test set. Consider using more expressive kernels (e.g., Matérn) or ensemble models. The FABO framework can also help by adapting the feature representation, which implicitly changes the model's landscape [2].
- Cause 3: Lack of Domain Knowledge Integration. The algorithm is purely data-driven without guidance from established scientific rules.
- Solution: Implement a framework like Reasoning BO, which uses knowledge graphs and LLMs to check the scientific plausibility of suggested experiments, filtering out those that violate domain constraints and guiding the search toward more promising regions [4].
- Cause 1: Overly Greedy Exploitation. The acquisition function's balance is skewed too heavily toward exploitation.
Problem: Optimization Progress is Slow Despite Many Experiments
- Symptoms: The number of experiments required to find a satisfactory optimum is high, negating the promised sample efficiency of BO.
- Possible Causes & Solutions:
- Cause 1: High Dimensionality of the Search Space. The "curse of dimensionality" makes modeling and searching the space exponentially harder.
- Solution: Apply feature selection or dimensionality reduction techniques before optimization if possible. Integrate the FABO framework to dynamically reduce the feature space dimensionality during the BO campaign itself [2].
- Cause 2: Inefficient Use of Resources. Waiting for each experiment to finish before starting the next is time-consuming.
- Solution: Utilize batch (parallel) Bayesian Optimization. Packages like Ax and BoTorch allow you to propose multiple experiments for parallel evaluation in a single cycle, dramatically reducing the total calendar time for the optimization campaign [13].
- Cause 1: High Dimensionality of the Search Space. The "curse of dimensionality" makes modeling and searching the space exponentially harder.
Problem: Model Predictions are Inaccurate and Poorly Guide the Search
- Symptoms: The surrogate model's predictions have large errors when compared to subsequent experimental results.
- Possible Causes & Solutions:
- Cause 1: Inadequate Initial Data or Strong Non-Linearities. The initial data is too sparse or the model is too simple.
- Cause 2: Improper Data Preprocessing. The scale of input variables or the target output can mislead the model.
- Solution: Standardize or normalize all input parameters (e.g., to zero mean and unit variance). Check the distribution of the target variable and apply transformations (e.g., log-transform) if necessary to make it more Gaussian-like, which often improves GP performance [16].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 2: Key Reagents and Materials for Bioprocess Optimization
| Reagent/Material | Function in Bioprocess Development | Application Example |
|---|---|---|
| CHO Cell Lines | Host cells for recombinant protein production (e.g., monoclonal antibodies). | Engineered cell lines optimized for prolonged fed-batch performance, enhanced glycosylation, and reduced metabolite secretion (e.g., lactate) [42]. |
| Mesenchymal Stromal Cells (MSC) | Critical cellular products for allogeneic cell therapies. | Expansion in single-use stirred-tank bioreactors using microcarriers for scalable, clinical-grade production [42]. |
| Microcarriers | Provide a surface for anchorage-dependent cells (e.g., MSCs) to grow in 3D bioreactor cultures. | Enables scalable expansion of cells in stirred-tank bioreactors, moving beyond traditional planar culture systems [42]. |
| Chromatography Resins | Purify target biologics (e.g., proteins, viruses) from complex mixtures based on properties like charge, hydrophobicity, or size. | Novel mixed-mode cation-exchange resins are being developed to enhance clearance of product-related impurities like aggregates in bispecific antibody purification [43]. |
| Virus Filters | A critical safety step to remove or inactivate viral contaminants from the product stream using size exclusion or other mechanisms. | Membrane filtration used for robust virus removal, ensuring patient safety for biologics produced in mammalian cells [43]. |
| Single-Use Bioreactors | Disposable culture vessels for upstream bioprocessing, reducing cross-contamination risk and cleaning validation needs. | Used for the scalable, GMP-compliant expansion of therapeutic cells like MSCs [42] [40]. |
Experimental Protocol: Implementing a Bayesian Optimization Campaign for a Fed-Batch Bioreactor Process
This protocol outlines the steps to optimize critical process parameters (CPPs) for a fed-batch bioreactor process to maximize cell density and product titer.
Objective: Maximize final product titer in a CHO cell fed-batch process. Key CPPs to Optimize:
- Initial glucose concentration (continuous: 2 - 8 g/L)
- Temperature shift day (continuous: Day 3 - 7)
- Feed supplement type (categorical: Supplement A, B, or C)
- pH setpoint (continuous: 6.8 - 7.2)
Procedure:
- Define the Experimental Space and Objective: Clearly delineate the bounds for your continuous parameters and the options for categorical parameters within the BO software (e.g., Summit, Ax). Define the objective as "Maximize Final Titer."
- Generate Initial Dataset: Use a space-filling design (e.g., Latin Hypercube) to generate 10-15 initial bioreactor runs. Execute these experiments, measure the final titer, and record the data.
- Configure the BO System:
- Surrogate Model: Choose a Gaussian Process (GP) model with a Matérn kernel, configured to handle mixed continuous/categorical parameters.
- Acquisition Function: Select Expected Improvement (EI) or Upper Confidence Bound (UCB). For a more exploratory start, use UB with a higher
βvalue (e.g., 3.0).
- Run the Optimization Loop: a. The BO algorithm suggests the next set of CPPs for a bioreactor run (or a batch of runs). b. Execute the bioreactor experiment(s) with the suggested parameters. c. Measure the final titer (the objective function). d. Feed the result (CPPs and resulting titer) back to the BO algorithm. e. The algorithm updates its surrogate model and suggests the next experiment.
- Terminate the Campaign: Continue the loop for a predetermined number of cycles (e.g., 20-30) or until the rate of improvement falls below a predefined threshold (e.g., <2% improvement over 5 consecutive runs).
Workflow and System Diagrams
Diagram 1: Bayesian Optimization Core Workflow
Diagram 2: Feature Adaptive BO (FABO) Process
Diagram 3: Reasoning BO System with LLM Agent
Frequently Asked Questions: Troubleshooting Your Bayesian Optimization Experiments
Q1: I am a chemist, not a machine learning expert. Which Bayesian optimization package should I start with for optimizing my chemical reactions?
A: For practitioners in chemistry, Summit is highly recommended. It is specifically designed for reaction optimization and provides a user-friendly interface, allowing you to focus on your experiment rather than the underlying algorithm [44]. It includes benchmarks to test strategies and is built to make machine learning more accessible for chemical applications [45].
Q2: When should I use BoTorch directly instead of a higher-level platform like Ax?
A: You should use BoTorch directly when you are a researcher working in a non-standard setting or when you need full control and understanding of the details in the BO loop, such as custom models or acquisition functions [46]. If you prefer a simplified interface for managing experiments, Ax is recommended as it uses BoTorch under the hood for its Bayesian optimization algorithms [47].
Q3: My objective involves comparing different experimental conditions rather than measuring a exact value. Can Bayesian optimization handle this?
A: Yes. BoTorch provides specialized models like the PairwiseGP for scenarios where data consists of pairwise comparisons. This is useful when it's easier to judge which of two outcomes is better than to assign an absolute quantitative score [48].
Q4: I work with molecular structures and need a kernel that can handle graph or fingerprint representations. Which library can help?
A: The GAUCHE library is specifically designed for this purpose. It provides a large collection of bespoke kernels for structured data in chemistry, including fingerprint, string, and graph kernels for molecules and reactions [49]. It integrates seamlessly with the GPyTorch and BoTorch ecosystems.
Q5: The performance of the TSEMO algorithm in Summit is slow for my problem. What can I do?
A: The computational time of TSEMO is significantly affected by the n_spectral_points parameter. The Summit documentation suggests reducing this value from its default of 1500 to speed up computation, though this may trade off some accuracy. For the best performance (if you can afford the time), increasing it to around 4000 is recommended [45].
Q6: How can I integrate my custom BoTorch model into a full experiment management system?
A: Use Ax's Modular BoTorch Interface. This allows you to leverage your custom BoTorch models and acquisition functions while benefiting from Ax's capabilities for experiment configuration, orchestration, and data management [47].
Experimental Protocols & Methodologies
Protocol 1: Single-Objective Reaction Optimization using Summit
This protocol outlines the steps to optimize a chemical reaction for a single objective (e.g., yield) using Summit's SOBO strategy.
- Problem Definition: Define your optimization
Domainby specifying the variables (e.g., temperature, concentration) and their bounds, as well as the objective(s) to be maximized or minimized [45]. - Strategy Initialization: Instantiate the SOBO strategy, passing the defined domain.
- Suggest Experiments: Use
suggest_experimentsto get a set of conditions to test. If available, pass data from previous experiments to inform the suggestion. - Run Experiments: Conduct the suggested experiments in the lab and record the results.
- Update Model: Provide the experimental results back to the strategy and repeat steps 3-5 until convergence or the experimental budget is exhausted.
Protocol 2: Multi-Objective Optimization with TSEMO in Summit
This protocol is for optimizing multiple, often competing, objectives (e.g., maximizing yield while minimizing cost) using the TSEMO algorithm in Summit [45].
- Domain Setup: Define a domain that includes multiple objectives.
- Strategy Initialization: Instantiate the TSEMO strategy with the domain.
- Iterative Optimization Loop:
- The algorithm trains a Gaussian Process (GP) model for each objective.
- It uses spectral sampling to draw a deterministic function from each GP.
- These functions are optimized with the NSGA-II algorithm to find a set of non-dominated solutions (Pareto front).
- Experiments are selected based on which conditions offer the best hypervolume improvement (HVI) to the Pareto front.
- The suggested experiments are run, and the data is used to update the models in the next iteration [45].
Protocol 3: Gaussian Process Regression on Molecules with GAUCHE
This protocol details how to build a GP model for molecular property prediction using a chemistry-aware kernel from the GAUCHE library [49].
- Data Loading and Featurization: Use GAUCHE's data loader to load and featurize a molecular dataset.
- Model Definition: Define a GP model using a kernel from GAUCHE, such as the Tanimoto kernel.
- Model Training and Fitting: Initialize the model and use a BoTorch utility to fit it.
- Prediction: Use the trained model to make predictions on new molecules.
Bayesian Optimization Package Comparison
The following table summarizes the key features of the three main software toolkits to help you select the right one for your project.
| Feature | Summit | BoTorch | GAUCHE |
|---|---|---|---|
| Primary Focus | Chemical reaction optimization [44] | Flexible Bayesian optimization research [47] | Gaussian processes for chemistry [49] |
| User Level | Practitioner / Scientist [44] | Researcher / Expert [46] | Researcher / Practitioner |
| Key Strength | User-friendly API, domain-specific benchmarks [44] [45] | High modularity, state-of-the-art algorithms [46] | Specialized kernels for molecules & reactions [49] |
| Integration | Uses GPy/GPyOpt, can leverage BoTorch models | Used by Ax, integrates with PyTorch | Builds on GPyTorch & BoTorch [49] |
| Multi-objective | Yes (e.g., TSEMO) [45] | Yes | Yes (via BoTorch) |
Bayesian Optimization Workflow
The following diagram illustrates the standard iterative workflow of a Bayesian optimization loop, common to all packages.
BO Experimental Workflow
Research Reagent Solutions: Essential Components for a BO Experiment
This table lists the core "reagents," or software components, required to set up a Bayesian optimization experiment, along with their functions.
| Research Reagent | Function / Purpose |
|---|---|
| Search Space/Domain | Defines the variables to be optimized and their constraints (e.g., continuous, categorical) [45]. |
| Objective Function | The expensive "black-box" function (e.g., reaction yield) that the BO aims to optimize [16]. |
| Surrogate Model | A probabilistic model (e.g., Gaussian Process) that approximates the objective function [16]. |
| Acquisition Function | A utility function that guides the search by balancing exploration and exploitation to suggest the next experiment [16] [45]. |
| Optimizer | An algorithm used to find the maximum of the acquisition function to select the next sample point [45]. |
Navigating Real-World Complexities: Troubleshooting and Advanced Optimization Strategies
Handling Noisy and Small Datasets in Bioprocess and Chemical Experiments
Frequently Asked Questions (FAQs)
FAQ 1: What are the primary data challenges when applying Bayesian optimization to bioprocess development? Data in bioprocess engineering often exhibits four key characteristics that complicate the use of classical machine learning approaches: (1) High variance, low volume: Datasets are often small but exhibit significant variability. (2) Low variance, high volume: In some automated systems, data is plentiful but lacks informative variation. (3) Noisy, corrupt, or missing data: Experimental errors, instrument sensitivity, and human factors can corrupt measurements. (4) Restricted data with physics-based limitations: Data collection is constrained by cost, time, or fundamental physical laws [50]. These issues are pronounced in biological systems where prediction accuracy is highly data-dependent [32].
FAQ 2: How can I determine if my dataset is too small or noisy for reliable Bayesian optimization? A key step is to analyze the intrinsic limitations of your dataset. For small datasets, performance bounds can be estimated by introducing noise based on known or estimated experimental errors [51]. If your current machine learning models are performing at or beyond these estimated bounds, they may be fitting noise rather than the true signal. This is a common issue in chemical sciences where data collection is costly and experimental errors can be significant [51].
FAQ 3: What specific techniques improve Bayesian optimization performance with limited data? Several advanced techniques have proven effective:
- Feature Adaptive Bayesian Optimization (FABO): Dynamically identifies the most informative molecular or material features during the optimization process itself, reducing reliance on large, pre-existing labeled datasets [2].
- Multi-fidelity Modeling: Uses cheaper, lower-fidelity data (e.g., from simulations or small-scale experiments) to inform the optimization of high-cost, high-fidelity experiments, drastically reducing resource consumption [52] [32].
- Scalable Multi-objective Acquisition Functions: For highly parallel experimentation, functions like q-NParEgo and Thompson Sampling with Hypervolume Improvement (TS-HVI) efficiently handle multiple objectives (e.g., yield and selectivity) with large batch sizes, making better use of limited experimental cycles [1].
FAQ 4: Our high-throughput experimentation (HTE) generates large condition spaces but few successful reactions. How can Bayesian optimization help? Bayesian optimization is uniquely suited for this challenge. It efficiently navigates large combinatorial reaction spaces (e.g., with 88,000 possible conditions) by using a Gaussian Process surrogate model to predict outcomes and an acquisition function to guide the search toward promising regions. This allows for the identification of optimal conditions by testing only a small, informative subset of all possible combinations, overcoming the limitations of exhaustive screening or traditional chemist-designed grids [1].
Troubleshooting Guide
The following table outlines common problems, their diagnostic signals, and recommended solutions based on current research.
| Problem | Diagnostic Signals | Recommended Solutions |
|---|---|---|
| Model Fitting Noise | Model performance meets or exceeds estimated dataset performance bounds [51]; High variance in model predictions with small data changes. | Quantify experimental error to establish realistic performance bounds [51]; Employ Gaussian Processes with Matérn kernels, which are robust to noise [32]; Use methods like FABO to select the most relevant features and reduce dimensionality [2]. |
| Inefficient Exploration in Large Search Spaces | Optimization stalls in local optima; Poor performance in high-dimensional spaces (e.g., many catalysts, solvents, ligands). | Implement adaptive representation frameworks like FABO [2]; Use scalable multi-objective acquisition functions (e.g., TS-HVI, q-NParEgo) for parallel HTE [1]; Start exploration with quasi-random Sobol sampling for broad coverage [1]. |
| High Experimental Cost per Data Point | Optimization budget exhausted with minimal improvement; Reluctance to run necessary experiments due to cost. | Integrate multi-fidelity Bayesian optimization to leverage cheaper data sources (e.g., computational simulations, low-fidelity assays) [52] [32]; Apply sequential model-based optimization to prioritize high-information experiments [32]. |
| Poor Generalization from Small Datasets | Models perform well on training data but fail to guide new experiments to improved outcomes. | Use surrogate models like Gaussian Processes that provide native uncertainty quantification, guiding exploration [32] [1]; Incorporate domain knowledge through knowledge graphs or pre-trained models to inform the search [4]. |
Detailed Experimental Protocols
Protocol 1: Implementing Feature Adaptive Bayesian Optimization (FABO)
This methodology is designed for tasks where the optimal material or molecular representation is unknown at the outset, such as optimizing Metal-Organic Frameworks (MOFs) for gas adsorption [2].
- Initialization: Begin with a complete, high-dimensional representation of your chemical system (e.g., including both chemical and geometric features for materials).
- Data Labeling: Perform an initial set of experiments or simulations to obtain target property values (e.g., CO₂ uptake, band gap).
- Feature Selection: At each Bayesian optimization cycle, apply a feature selection algorithm to the currently acquired data. Common methods include:
- Model Update: Update the Gaussian Process surrogate model using the adaptively selected feature subset.
- Candidate Selection: Use an acquisition function (e.g., Expected Improvement) to select the next experiment.
- Iteration: Repeat steps 2-5 until convergence or budget exhaustion [2].
Protocol 2: A Workflow for Highly Parallel Reaction Optimization
This protocol, based on the "Minerva" framework, is designed for automated high-throughput experimentation platforms [1].
- Define Search Space: Enumerate a discrete combinatorial set of plausible reaction conditions (reagents, solvents, temperatures), automatically filtering out impractical or unsafe combinations.
- Initial Sampling: Use algorithmic quasi-random Sobol sampling to select an initial batch of experiments (e.g., a 96-well plate) that maximizes diversity and coverage of the reaction space.
- Model Training & Multi-Objective Selection: Train a Gaussian Process regressor on the collected data. Then, use a scalable multi-objective acquisition function like TS-HVI or q-NParEgo to select the next large batch of experiments, balancing the goals (e.g., yield, selectivity).
- Iterative Learning: Run the new batch of experiments, update the model with the results, and repeat the process. Integrate chemist domain expertise between cycles to refine the search strategy [1].
Workflow Visualization
The following diagram illustrates the iterative cycle of a Bayesian optimization framework, such as FABO, that incorporates adaptive feature handling.
Diagram 1: Feature-adaptive Bayesian optimization workflow for handling small datasets.
The Scientist's Toolkit: Key Research Reagents & Solutions
This table lists critical computational tools and methodological "reagents" essential for implementing robust Bayesian optimization campaigns with imperfect data.
| Item | Function / Application |
|---|---|
| Gaussian Process (GP) Surrogate Model | A probabilistic model that serves as the core surrogate in BO, valued for its native uncertainty quantification with small datasets [32] [1]. The Matérn kernel (ν=5/2) is often preferred over the RBF kernel for modeling chemical and physical processes [32]. |
| Feature Selection Algorithms (mRMR, Spearman) | Computational methods used within frameworks like FABO to dynamically identify the most relevant features from a large pool, reducing dimensionality and mitigating overfitting [2]. |
| Multi-Objective Acquisition Functions (TS-HVI, q-NParEgo) | Algorithms that guide the selection of experiments when optimizing for multiple, competing objectives (e.g., yield and cost). They are engineered for scalability in high-throughput environments [1]. |
| Sobol Sequence | A quasi-random sampling algorithm used to generate initial experimental designs that provide uniform coverage of the search space, ensuring a robust starting point for optimization [1]. |
| Multi-Fidelity Modeling | A strategy that integrates data of varying cost and accuracy (e.g., computational screening vs. lab validation) to reduce the total experimental cost of an optimization campaign [52] [32]. |
Strategies for High-Dimensional and Categorical Parameter Spaces
This guide addresses common challenges and solutions when applying Bayesian Optimization (BO) to complex chemical hyperparameter tuning tasks, focusing on high-dimensional and categorical parameter spaces.
Frequently Asked Questions
What are the main reasons Bayesian Optimization struggles with high-dimensional problems?
BO performance often deteriorates in spaces with more than approximately 20 dimensions due to the curse of dimensionality [53]. The volume of the search space grows exponentially with each additional dimension, requiring exponentially more samples to achieve adequate coverage [53]. Without strong structural assumptions about the objective function, BO cannot efficiently locate promising regions in vast, high-dimensional spaces [53].
How can I improve BO performance for high-dimensional chemical parameter tuning?
Effective strategies involve making structural assumptions to reduce the effective search space dimensionality [53]. Key approaches include:
- Sparsity: Assuming only a subset of the parameters significantly impacts the objective [53].
- Low-Dimensional Projections: Using linear or nonlinear projections to embed the high-dimensional space into a lower-dimensional manifold [53].
- Specialized Priors: Employing surrogate models designed for high-dimensional settings, such as Sparse Axis-Aligned Subspaces [53]. Success has been demonstrated in optimizing a 41-parameter coarse-grained model, indicating that with proper techniques, BO can be applied beyond the 20-dimensional threshold [54].
What are common pitfalls that cause BO to fail, even in lower dimensions?
Even in lower-dimensional problems, BO can perform poorly due to several easily overlooked configuration issues [22] [55]:
- Incorrect Prior Width: The Gaussian Process prior must accurately reflect the scale of the objective function.
- Over-Smoothing: An inappropriate kernel lengthscale can cause the surrogate model to overlook important, sharp features of the objective landscape.
- Inadequate Acquisition Maximization: Failure to properly optimize the acquisition function itself can lead to suboptimal suggestion of the next experiment [22] [55]. Addressing these issues can enable even a basic BO setup to achieve state-of-the-art performance on benchmarks like molecule design [22] [55].
How should I handle categorical parameters, like solvent or ligand choice?
Categorical parameters require special representation within the surrogate model. A common and effective approach is to treat the combinatorial space of plausible reaction conditions as a discrete set [1]. This allows for the integration of domain knowledge to filter out impractical combinations (e.g., unsafe reagent-solvent pairs) a priori. The optimization then selects from this predefined set of viable condition combinations [1].
Troubleshooting Guides
Problem: Poor Convergence in High-Dimensional Spaces
Diagnosis: The algorithm is unable to locate improving regions of the search space within a reasonable budget of experiments, often due to the vastness of the parameter space [53].
Solutions:
- Implement Dimensionality Reduction: Apply techniques like Principal Component Analysis (PCA) or non-linear autoencoders if you suspect the effective dimensionality is lower [53].
- Use High-Dimensional BO Algorithms: Employ modern methods like SAASBO (Sparse Axis-Aligned Subspaces) or those that leverage low-dimensional feature spaces, which explicitly assume sparsity [53].
- Incorporate Expert Knowledge: Manually fix or narrow the ranges of parameters known to be less critical, thereby reducing the active search space.
Experimental Protocol (Sparsity Assumption):
- Objective: Optimize a reaction yield over a large set of potential continuous and categorical parameters.
- Method: Use the SAASBO algorithm, which places a strong sparsity-promoting prior on the inverse lengthscales of the Gaussian Process. This automatically identifies the most relevant parameters.
- Evaluation: Compare the convergence speed and final performance against a standard BO baseline on a simulated or historical dataset.
Problem: Inefficient Optimization with Many Categorical Variables
Diagnosis: The presence of numerous categorical parameters (e.g., solvent, catalyst, ligand) creates a complex, non-smooth landscape with potentially isolated optima, which standard kernels like RBF struggle to model [1].
Solutions:
- Use Specialized Kernels: Replace the standard RBF kernel with one designed for categorical data, such as the Hamming kernel or a kernel defined over a molecular descriptor space.
- Adopt a Discrete Workflow: Frame the problem as selection from a large but finite set of pre-defined condition combinations, as done in the Minerva framework [1].
- Leverage Chemical Descriptors: Represent categorical choices (e.g., ligands) using continuous molecular descriptors (e.g., topological indices, electronic parameters), converting the problem into a continuous optimization.
Experimental Protocol (Discrete Combinatorial Search):
- Objective: Maximize yield and selectivity for a Ni-catalyzed Suzuki reaction across 88,000 possible condition combinations [1].
- Method:
- Define the search space as a discrete set of plausible conditions, filtering out unsafe or impractical combinations.
- Use quasi-random Sobol sampling for the initial batch to maximize diversity.
- Train a Gaussian Process surrogate model on the collected data.
- Use a scalable multi-objective acquisition function (e.g., q-NParEgo, TS-HVI) to select the next batch of experiments in a 96-well plate [1].
- Evaluation: Track the hypervolume of the Pareto front over several iterative batches to measure multi-objective optimization progress [1].
Problem: BO Gets Stuck in Local Optima
Diagnosis: The acquisition function becomes overly greedy, exploiting a small region and failing to explore more promising, distant areas of the search space.
Solutions:
- Adjust the Acquisition Function: Increase the weight on the "exploration" component. For UCB, this means increasing the
βparameter [22]. - Incorporate Domain Knowledge: Use LLM-augmented frameworks like "Reasoning BO" to guide the search based on chemical priors and hypotheses, helping to escape local optima dictated by data alone [4].
- Restart with Different Initialization: If stagnation is detected, restart the optimization process with a new set of initial points to cover different regions.
Performance Data and Algorithm Selection
Table 1: Scalability of Multi-Objective Acquisition Functions
The choice of acquisition function is critical for parallel (batch) optimization. The following table compares options suitable for high-throughput experimentation (HTE) [1].
| Acquisition Function | Scalability (Batch Size) | Key Principle | Best For |
|---|---|---|---|
| q-NParEgo | High | Extends ParEGO for parallel evaluation via random scalarization [1]. | Large batch sizes (e.g., 96-well plates) with multiple objectives [1]. |
| TS-HVI | High | Uses Thompson Sampling for candidate selection and hypervolume improvement [1]. | Scalable multi-objective optimization where q-EHVI is too slow [1]. |
| q-NEHVI | Medium | Computes expected hypervolume improvement for q parallel experiments [1]. | Smaller batches where computational cost is acceptable for precise sampling. |
Table 2: Technical Specifications of Featured Optimization Frameworks
| Framework / Concept | Key Innovation | Reported Application / Performance |
|---|---|---|
| Reasoning BO [4] | Integrates LLMs for hypothesis generation and uses knowledge graphs for dynamic knowledge accumulation. | Increased chemical reaction yield to 60.7%, compared to 25.2% with traditional BO [4]. |
| Minerva [1] | A scalable ML framework for highly parallel multi-objective optimization integrated with automated HTE. | Optimized a Ni-catalyzed Suzuki reaction in a 96-well plate, finding conditions with 76% yield/92% selectivity where traditional HTE failed [1]. |
| High-Dimensional BO [54] | Application of BO to a parameter space exceeding 20 dimensions. | Successfully parameterized a 41-parameter coarse-grained molecular model, achieving convergence in <600 iterations [54]. |
Workflow Diagrams
Bayesian Optimization Core Loop
High-Dimensional Strategy
The Scientist's Toolkit
Table 3: Key Research Reagent Solutions
| Item | Function in Bayesian Optimization |
|---|---|
| Gaussian Process (GP) | A probabilistic model serving as the core surrogate function for predicting the objective and its uncertainty [22] [1]. |
| Expected Improvement (EI) | An acquisition function that suggests the next experiment by balancing the potential value of improvement against its uncertainty [22]. |
| Sobol Sequence | A quasi-random sampling method used to generate a diverse, space-filling initial dataset before starting the iterative BO loop [1]. |
| Knowledge Graph | A structured knowledge base used in advanced frameworks like Reasoning BO to store domain rules and experimental insights, preventing nonsensical suggestions [4]. |
| Multi-Objective AF | An acquisition function (e.g., q-NEHVI, TS-HVI) designed to handle multiple, often competing, objectives like maximizing yield while minimizing cost [1]. |
FAQs
1. What are Advanced Acquisition Functions (AFs) and why are they needed for complex goals? Standard acquisition functions like Expected Improvement (EI) are designed for single-objective optimization. Advanced AFs are necessary when your experiment has multiple, competing objectives (e.g., maximizing yield while minimizing cost and waste) or involves complex constraints. They provide a structured strategy to efficiently navigate the trade-offs between these goals and identify a set of optimal solutions, known as the Pareto front, rather than a single best point [16] [56].
2. When should I use TSEMO versus qNEHVI for multi-objective Bayesian optimization? Your choice depends on your specific needs regarding performance and computational speed. TSEMO (Thompson Sampling Efficient Multi-Objective) is known for its strong performance and has been successfully used in various chemical synthesis optimizations [16] [57]. However, it can be computationally expensive. qNEHVI (q-Noisy Expected Hypervolume Improvement) is a more recent state-of-the-art algorithm that offers robust performance with a significant reduction in computational time per iteration, making it highly suitable for practical laboratory settings [56] [57]. A benchmark study on a Schotten–Baumann reaction found qNEHVI achieved similar hypervolume performance as TSEMO but was over 20 times faster [57].
3. What does "subset-selection" refer to in the context of Bayesian optimization? Subset-selection addresses the challenge of identifying the most important variables or parameters from a larger set, especially when data is limited. From a Bayesian perspective, it involves curating a family of near-optimal subsets of variables rather than relying on a single "best" subset. This approach provides a more complete and stable picture, revealing that many different combinations of variables can lead to similarly high predictive performance—a phenomenon known as the Rashomon effect. This is particularly valuable for interpretable learning and scientific discovery [58] [59].
4. My optimization is stuck in a region of infeasible solutions. How can the algorithm handle constraints? Advanced algorithms like qNEHVI and hybrid frameworks such as EGBO (Evolution-Guided Bayesian Optimization) can incorporate knowledge of constraints directly into the optimization process. They learn the boundaries of feasible regions from experimental data and use this information to guide the search away from conditions that would violate constraints (e.g., those that cause equipment clogging or unsafe reactions). The EGBO algorithm, for instance, has demonstrated a better ability to propose feasible solutions while efficiently exploring the Pareto front [56].
5. How do I manage both continuous and categorical variables in the same optimization? It is possible to optimize over a mix of variables. For example, a study on the Schotten–Baumann reaction simultaneously optimized continuous variables (like flow rate and reagent equivalents) and categorical variables (like solvent and electrophile choice). The typical methodology involves using one-hot encoding for the categorical variables and incorporating them into the Gaussian process model. Strategies like the "rounding trick" can then be used during the optimization of the acquisition function to handle these mixed variable types effectively [57].
Troubleshooting Guides
Issue 1: Poor Convergence or Slow Progress in Multi-Objective Optimization
Problem: The optimization process is not efficiently moving towards the Pareto front, or the hypervolume improvement has stagnated.
| Potential Cause | Recommended Solution |
|---|---|
| Insufficient initial data for building accurate surrogate models. | Use a space-filling design like MaxPro (Maximum Projection) for your initial experiments. This design works well with mixed variable types and provides a good foundation for the Gaussian process [57]. |
| The algorithm is over-exploring and wasting experiments on regions of low promise. | Consider a hybrid algorithm like Evolution-Guided Bayesian Optimization (EGBO), which integrates selection pressure from an evolutionary algorithm to focus the search more effectively and limit sampling in infeasible or poor-performing spaces [56]. |
| The acquisition function is not suited for the problem's complexity. | Switch to a more advanced AF like qNEHVI. It is robust to noise and efficiently handles the exploration-exploitation trade-off for multiple objectives, often leading to faster convergence [56] [57]. |
Issue 2: Handling Complex Constraints and Infeasible Regions
Problem: The algorithm repeatedly suggests experimental conditions that are impractical, unsafe, or violate known constraints.
| Potential Cause | Recommended Solution |
|---|---|
| Constraints are not explicitly defined in the optimization framework. | Formulate your constraints clearly and integrate them into the objective function or the optimizer's logic. For example, you can use a gate function to set the objective value to zero if a measurement falls outside a feasible operating range [56]. |
| The algorithm needs to learn the feasible space. | Use an optimizer like EGBO or qNEHVI that is designed to model and handle constraint functions. These algorithms can learn the boundaries of the feasible region from data and reduce the number of infeasible suggestions over time [56]. |
Issue 3: High Computational Cost of the Optimization Algorithm
Problem: The time taken by the algorithm to suggest the next experiments is impractically long for your workflow.
| Potential Cause | Recommended Solution |
|---|---|
| The acquisition function is computationally expensive to optimize. | Benchmark your algorithm. If using TSEMO, switching to qNEHVI can drastically reduce computation time because it uses gradient-based optimization instead of genetic algorithms like NSGA-II [57]. |
| The batch selection process is inefficient. | Implement efficient parallelization strategies. The "q" in qNEHVI stands for the number of parallel experiments it can propose in one batch, which helps utilize high-throughput platforms without a linear increase in computational overhead [16] [56]. |
Experimental Protocols & Data Presentation
Benchmarking TSEMO and qNEHVI for a Chemical Reaction
Objective: To compare the performance of TSEMO and qNEHVI in optimizing a multi-objective chemical synthesis problem.
Methodology (as applied to the Schotten–Baumann reaction [57]):
- Define Objectives and Variables: The goal was to maximize Space–Time Yield (STY) and minimize E-factor. Variables included both continuous (flow rate, reagent equivalents) and categorical (electrophile, solvent) parameters.
- Initial Design: Generate an initial dataset of 20 experiments using a Maximum Projection (MaxPro) design.
- Algorithm Configuration: Run both TSEMO and qNEHVI, starting from the same initial data, and allow each to suggest 20 additional experiments.
- Performance Metric: Calculate the hypervolume after each iteration to track the progress toward the Pareto front. Repeat the process multiple times (e.g., 20 runs) to establish statistical significance.
Results: The study provided a quantitative comparison of the two algorithms' performance and efficiency.
Table 1: Benchmarking Results for TSEMO vs. qNEHVI [57]
| Algorithm | Hypervolume Performance | Average Time per Iteration | Key Characteristics |
|---|---|---|---|
| TSEMO | High | 121.5 seconds | Uses Thompson sampling & NSGA-II; strong performance but computationally expensive [16] [57]. |
| qNEHVI | High (similar to TSEMO) | 5.1 seconds | Uses gradient-based optimization; robust to noise; significantly faster than TSEMO; state-of-the-art for constrained multi-objective problems [57]. |
Protocol for Multi-objective Optimization with qNEHVI
The following workflow diagram outlines the iterative "closed-loop" process of Bayesian optimization, which is central to protocols using advanced AFs like qNEHVI or TSEMO.
Application of Subset-Selection in a Predictive Model
Objective: To identify a family of near-optimal subsets of variables for predicting educational outcomes, demonstrating the principle of Bayesian subset selection [59].
Methodology:
- Define Predictive Model ((\mathcal{M})): Establish a Bayesian linear regression model as the base predictive model.
- Optimal Coefficients: For any given subset of variables, derive the optimal linear coefficients using Bayesian decision analysis. These coefficients inherit regularization and uncertainty quantification from the parent model (\mathcal{M}).
- Subset Search: Use a modified branch-and-bound algorithm to efficiently explore the space of all possible variable subsets.
- Curate Acceptable Family: Collect all subsets that demonstrate near-optimal predictive performance based on a pre-defined out-of-sample metric, acknowledging the Rashomon effect.
- Summarize Results: Analyze the "acceptable family" of subsets by reporting key members (e.g., the smallest acceptable subset) and calculating new (co-)variable importance metrics based on how frequently variables appear in the acceptable subsets.
Results: This approach, when applied to a dataset with highly correlated covariates, identified over 200 distinct subsets that offered near-optimal predictive accuracy. This provides a more robust and interpretable outcome than relying on a single "best" model [59].
The Scientist's Toolkit: Research Reagent Solutions
The following table lists key materials and their functions from the seed-mediated silver nanoparticle synthesis case study, which was optimized using the EGBO algorithm [56].
Table 2: Key Reagents for Seed-Mediated Silver Nanoparticle Synthesis [56]
| Reagent / Material | Function in the Experiment |
|---|---|
| Silver Seeds | Act as nucleation sites for the growth of larger nanoparticles; their concentration is minimized to reduce costs [56]. |
| Silver Nitrate (AgNO₃) | Source of silver ions for the reduction and growth onto the seed particles [56]. |
| Ascorbic Acid (AA) | Serves as a reducing agent, converting silver ions (Ag⁺) to metallic silver (Ag⁰) [56]. |
| Trisodium Citrate (TSC) | Functions as a stabilizing agent (capping agent) to control particle growth and prevent aggregation [56]. |
| Polyvinyl Alcohol (PVA) | Acts as a stabilizer and can also influence the viscosity and droplet formation in microfluidic systems [56]. |
| Microfluidic Droplet Platform | Enables high-throughput screening by creating isolated reaction environments (droplets) for parallel experimentation [56]. |
| Line-Scan Hyperspectral Imaging System | Provides in-situ characterization of the nanoparticles by capturing their UV/Vis spectral signatures to track reaction progress and outcomes [56]. |
Incorporating Prior Knowledge and Expert Preference into the BO Loop
Frequently Asked Questions (FAQs)
1. Why should I incorporate my expert knowledge into Bayesian Optimization? Integrating your expertise helps overcome key limitations of standard BO. It can prevent the algorithm from getting trapped in local optima, reduce sensitivity to initial sampling, and avoid scientifically implausible or unsafe suggestions that may arise from purely data-driven search. This is crucial in chemical applications where domain knowledge exists about realistic reaction conditions or stable molecular structures [4] [12].
2. What forms can prior knowledge take when provided to the BO loop? Prior knowledge can be provided in several forms:
- Confidence about Regions: An expert can specify which regions of the search space are more likely to contain the optimum [60].
- Historical Optimization Data: The sequence of choices made by a human expert while solving a similar optimization problem can be used to infer their tacit knowledge [61].
- Structured Scientific Rules: Domain rules, such as chemical reaction rules or stability constraints, can be encoded into knowledge graphs or used to filter suggestions [4].
- Hypotheses: LLM-powered agents can generate and iteratively refine scientific hypotheses based on domain literature and experimental data [4].
3. My prior belief about the optimum was incorrect. Will this ruin the optimization?
Not necessarily. Robust methods like α-πBO are designed to leverage high-quality priors for faster convergence while maintaining performance close to standard BO even when the provided prior knowledge is misleading or of poor quality. This robustness makes it safe to integrate your hypotheses without the risk of catastrophic failure [60].
4. How can I include expert knowledge without a complex mathematical formulation? Modern frameworks allow for seamless integration. You can use a Prior-Weighted Acquisition Function, where your expert insight is distilled into a "fixed-weight effective prior." This prior directly and efficiently biases the acquisition function toward your regions of interest with minimal computational overhead and often no need for additional hyperparameter tuning [60].
5. We work with high-dimensional formulations. Can we still use these methods? Yes, but the approach may differ. For high-dimensional spaces, directly specifying a prior on all parameters can be challenging. In such cases, Reasoning BO frameworks that use knowledge graphs and multi-agent systems to manage and apply knowledge can be more effective than manual prior specification [4]. Alternatively, methods like SAASBO, which assume only a sparse subset of parameters are truly important, can be effective [62].
Troubleshooting Guides
Issue 1: BO Suggestions Are Chemically Impractical or Unsafe
Problem: The algorithm is suggesting parameter combinations (e.g., catalyst and solvent pairs) that are known to be unstable, dangerous, or chemically impossible.
Solution A: Implement a Knowledge-Based Filter
- Methodology: Introduce a pre-screening step for all BO suggestions before they are validated in experiment.
- Procedure:
- Encode domain knowledge as a set of rules (e.g., "Solvent A is incompatible with Catalyst B").
- Program an automatic filter based on these rules.
- Configure the BO loop so that any suggestion triggering a rule is discarded, and the acquisition function is queried again for a new candidate.
- Supporting Evidence: This approach mirrors the "confidence-based filtering" used in Reasoning BO, where an LLM evaluator assigns confidence scores to candidates, and low-confidence (scientifically implausible) suggestions are filtered out [4].
Solution B: Use an Interpretable Model with Embedded Constraints
- Methodology: Replace the standard Gaussian Process surrogate with a model that can more naturally incorporate domain knowledge and provide explainable outputs.
- Procedure:
- Adopt a sequential learning platform using Random Forests with advanced uncertainty quantification.
- Leverage built-in tools like feature importance and Shapley values to understand which parameters drive each prediction.
- The model can be adapted to include chemical rules, reducing the risk of "naïve" suggestions from the start [12].
- Comparison of Solutions:
| Solution | Best For | Key Advantage | Potential Drawback |
|---|---|---|---|
| Knowledge-Based Filter | Problems with clear, discrete compatibility rules. | Simple to implement and understand. | Requires explicit, pre-defined rule coding. |
| Interpretable Model | Complex, high-dimensional spaces where relationships are harder to codify. | Provides explanations for suggestions, building trust and scientific insight. | May require a more specialized software platform [12]. |
Issue 2: Optimization Gets Stuck Despite Expert Guidance
Problem: Even after guiding the BO toward a promising region, the optimization converges to a local optimum and fails to find a better solution.
Solution: Enhance the Framework with Dynamic Knowledge Management
- Methodology: Move from a static prior to a system that accumulates and refines knowledge throughout the optimization process.
- Procedure: Implement a framework like Reasoning BO, which includes:
- A Multi-Agent System where different AI agents take on roles (e.g., hypothesizer, critic) to generate and debate ideas.
- A Dynamic Knowledge Graph that stores structured information from domain literature and, crucially, new experimental discoveries from the BO loop itself.
- Retrieval-Augmented Generation (RAG) to fetch relevant knowledge from the database when evaluating new candidates [4].
- Experimental Protocol: In a benchmark study on the Direct Arylation reaction, this method achieved a final yield of 94.39%, compared to 76.60% for traditional BO, demonstrating its ability to escape local optima and find superior solutions [4].
The following diagram illustrates the closed-loop process of this dynamic knowledge management system.
Problem: You need to optimize for multiple objectives (e.g., high yield, low cost, low toxicity) and want to steer the solution based on expert preference.
Solution: Utilize Multi-Objective Bayesian Optimization (MOBO) with a Scalarization Strategy
- Methodology: Transform the multi-objective problem into a single-objective one using a scalarized function that reflects your expert preferences.
- Procedure:
- Define the relative importance (weights) of each objective based on expert judgment. For example, you might assign a higher weight to yield and a lower weight to cost.
- Use a scalarized combination of the objectives (e.g., a weighted sum) as the single target for the BO loop.
- The BO algorithm will then search for a single solution that best satisfies this weighted combination of goals [62].
- Alternative Approach: If you wish to see a range of options, you can use a MOBO algorithm like TSEMO (Thompson Sampling Efficient Multi-Objective) to map the Pareto front—the set of solutions where no objective can be improved without worsening another. An expert can then select the most preferred solution from this front [16].
The Scientist's Toolkit: Key Research Reagents & Solutions
The table below lists essential computational and methodological "reagents" for incorporating prior knowledge into BO.
| Item | Function & Purpose | Key Characteristics |
|---|---|---|
| α-πBO (Prior-Biased AF) [60] | Biases the acquisition function using expert-defined priors for faster convergence. | Robust to poor priors, minimal tuning, simple integration. |
| Knowledge Graph [4] | Stores structured domain knowledge (rules, literature) and experimental results for dynamic reasoning. | Enables continuous learning, supports RAG. |
| Multi-Agent System [4] | Generates and critiques hypotheses by simulating different expert roles. | Enhances reasoning, reduces risk of flawed suggestions. |
| Random Forest Surrogate [12] | An alternative surrogate model offering high interpretability and native handling of complex constraints. | Provides feature importance, faster in high dimensions. |
| TSEMO Algorithm [16] | An acquisition function for multi-objective problems that finds a diverse set of Pareto-optimal solutions. | Efficient for handling multiple, competing objectives. |
| Confidence-Based Filtering [4] | Screens BO suggestions for scientific plausibility before experimental validation. | Prevents wasteful/hazardous experiments, ensures safety. |
Frequently Asked Questions (FAQs)
FAQ 1: Why does my Bayesian Optimization (BO) campaign perform poorly even with an accurate surrogate model on training data? Your surrogate model may be suffering from the curse of dimensionality or may have learned an incomplete representation of the material or molecular search space. A model with high dimensionality can lead to poor BO performance. Furthermore, using a fixed, suboptimal feature set can introduce bias and prevent the model from identifying key relationships in a novel optimization task [2]. It is recommended to integrate feature selection directly into the BO loop. Frameworks like Feature Adaptive Bayesian Optimization (FABO) can dynamically identify the most informative features at each cycle, enhancing overall efficiency [2].
FAQ 2: How can I make my surrogate model more robust against real-world measurement uncertainties? Models trained on clean simulation data often fail when confronted with real-world noise. To enhance robustness, you should explicitly optimize for it during model training. Employ Multi-Objective Hyperparameter Optimization (MOHPO) to simultaneously tune your model for both prediction accuracy and robustness against input perturbations [63]. This model-agnostic strategy generates a Pareto front of solutions, allowing you to select a model that offers the best trade-off between performance and resilience to measurement uncertainties, such as temperature fluctuations in a manufacturing process [63].
FAQ 3: My optimization involves categorical variables (e.g., catalyst choice). How can I handle these effectively? While some BO frameworks are designed for continuous spaces, a practical workaround for categorical variables like solvent or catalyst choice is to reframe the problem as one of mixture optimization (e.g., binary or ternary solvent mixtures) [27]. Alternatively, you may consider leveraging specialized Bayesian Optimization algorithms that are capable of natively handling categorical and continuous inputs simultaneously [16].
FAQ 4: What is the benefit of using a multi-fidelity modeling approach in BO? Multi-fidelity Bayesian Optimization can significantly improve optimization efficiency by leveraging cheaper, lower-fidelity data sources (e.g., coarse simulations or short experiments) to guide the search, while reserving expensive, high-fidelity evaluations for the most promising candidates [52]. This approach has been shown to achieve better convergence and more stable performance while using fewer resources and less time compared to standard BO [52].
FAQ 5: How do I balance exploration and exploitation when tuning the acquisition function? The balance is managed by the acquisition function itself, but its behavior can be tuned. Functions like Upper Confidence Bound (UCB) have an explicit parameter to weight the exploration term. You can adjust this parameter to adopt a more risk-averse (favoring exploitation) or risk-seeking (favoring exploration) strategy based on your experimental costs and goals [26]. Furthermore, advanced frameworks may offer modular acquisition function selection, allowing you to choose the most appropriate function (e.g., Expected Improvement, Probability of Improvement) for your specific problem [26].
Troubleshooting Guides
Issue 1: Slow or Failed Convergence in High-Dimensional Spaces
Symptoms: The optimization process requires an excessive number of iterations, fails to improve upon the initial best result, or consistently gets stuck in local optima.
Diagnosis and Solution: This is frequently caused by the "curse of dimensionality," where a high-dimensional feature space makes it difficult for the surrogate model to form accurate predictions. The solution is to refine the feature space and ensure the model's receptive field is appropriately tuned.
| Diagnostic Step | Solution Protocol | Key References |
|---|---|---|
| Check Feature Space Dimensionality: Start with a complete but high-dimensional feature set. | Implement Dynamic Feature Selection: Integrate a feature selection method like Maximum Relevancy Minimum Redundancy (mRMR) or Spearman ranking into the BO loop. Adapt the representation at each cycle using only the data acquired during the campaign [2]. | FABO Framework [2] |
| Assume Model Receptive Field is Fixed: The Gaussian Process kernel's length scale may be inappropriate for the feature space. | Tune Kernel Hyperparameters: Use MOHPO to optimize the kernel's length scales. This adjusts the model's receptive field, improving its ability to generalize in high-dimensional spaces [2]. | Gaussian Process Tuning [2] |
Issue 2: Poor Surrogate Model Generalization to Noisy Experimental Data
Symptoms: The surrogate model shows high accuracy on noise-free training/simulation data but its predictive performance degrades significantly when applied to real experimental data containing measurement noise.
Diagnosis and Solution: The model has overfitted to idealized simulation data and lacks robustness against the natural perturbations present in any laboratory or production environment.
| Diagnostic Step | Solution Protocol | Key References |
|---|---|---|
| Quantify Real-World Robustness: Use Monte Carlo sampling to simulate measurement uncertainties (e.g., ±3°C temperature noise) and evaluate model performance under these conditions [63]. | Implement Multi-Objective Hyperparameter Optimization (MOHPO): During hyperparameter tuning, simultaneously optimize for both prediction accuracy (e.g., Mean Squared Error) and robustness. Select the final model from the resulting Pareto front [63]. | Robust Surrogate Modeling [63] |
| Verify Model Performance on Noisy Data: The model's loss function may not account for heteroscedastic (non-constant) noise. | Incorporate Heteroscedastic Noise Modeling: Use a surrogate model that can explicitly account for variable noise levels across the input space, which is common in biological and chemical data [26]. | BioKernel Framework [26] |
Issue 3: Inefficient Optimization with Expensive Experimental Evaluations
Symptoms: Each experimental evaluation (e.g., a chemical reaction or material synthesis) is resource-intensive, making the overall BO campaign prohibitively slow or costly.
Diagnosis and Solution: The standard BO procedure is not accounting for the cost of evaluations. The solution is to leverage strategies that maximize information gain per experiment and to consider cheaper sources of data.
| Diagnostic Step | Solution Protocol | Key References |
|---|---|---|
| Identify Availability of Lower-Fidelity Data: Check if cheaper, approximate data sources are available (e.g., coarse simulations, preliminary screening assays). | Adopt a Multi-Fidelity BO Approach: Use low-fidelity data to guide the optimization, reserving high-fidelity evaluations only for the most promising candidates. This has been shown to achieve superior performance with fewer high-cost experiments [52]. | Multifidelity BO [52] |
| Evaluate Experimental Modality: Experiments are conducted one-at-a-time in a batch reactor, leading to long campaign times. | Leverage Dynamic Flow Experiments (DynE): In flow chemistry, use dynamic experiments where parameters are changed over time. This generates rich datasets more efficiently, saving both reagents and time. Integrate DynE within a BO framework (e.g., DynO) [27]. | DynO Framework [27] |
Research Reagent Solutions: Essential Materials for Optimization Experiments
The following table details key computational and experimental "reagents" used in advanced Bayesian Optimization campaigns.
| Research Reagent | Function in Optimization | Example Use Case |
|---|---|---|
| Feature Selection Algorithms (mRMR, Spearman) | Dynamically identifies the most informative features from a high-dimensional pool during BO, improving sample efficiency and preventing bias [2]. | Metal-Organic Framework (MOF) discovery where different properties (CO2 uptake, band gap) are governed by distinct chemical/geometric features [2]. |
| Multi-Objective Hyperparameter Optimization (MOHPO) | Systematically tunes surrogate model hyperparameters to balance competing objectives, such as prediction accuracy and robustness to input noise [63]. | Creating robust surrogate models for glass forming processes that maintain accuracy despite temperature measurement uncertainties of ±3°C [63]. |
| Trust-Region Filter (TRF) | A solution strategy that improves the reliability of surrogate-based optimization by ensuring iterative steps remain within a region where the model is trustworthy [64]. | Optimizing CO2 pooling problems where surrogate models like Kriging and Artificial Neural Networks (ANNs) achieve fast convergence within a TRF framework [64]. |
| Heteroscedastic Noise Model | A Gaussian Process prior that accounts for non-constant measurement uncertainty across the input space, leading to more realistic uncertainty quantification [26]. | Optimizing biological systems like astaxanthin production in E. coli, where experimental noise is inherently variable [26]. |
| Multi-Fidelity Surrogate Models | Leverages cheaper, lower-fidelity data to approximate the objective function, dramatically reducing the number of costly high-fidelity evaluations required [52]. | Hyperparameter tuning for deep reinforcement learning algorithms, where multi-fidelity BO outperformed standard BO in convergence and stability [52]. |
Benchmarking Performance: Validation and Comparative Analysis of Bayesian Optimization
Frequently Asked Questions (FAQs)
Q1: When should I choose Bayesian Optimization over traditional methods like DoE for my chemical process? Bayesian Optimization (BO) is particularly well-suited for problems where experiments are costly or time-consuming, the objective function is a black box, and the search space is complex with potential non-linear interactions [32] [26]. It excels in sample efficiency, often finding global optima with fewer experiments compared to traditional methods. However, for simpler systems with a low number of variables or when a clear mathematical model is available, traditional Design of Experiments (DoE) may be more straightforward to implement and interpret [32] [65].
Q2: Why is my Bayesian Optimization algorithm getting stuck in a local optimum or performing poorly? Several common issues can cause this:
- Incorrect Prior Width: An improperly specified prior in the surrogate model can bias the search [23].
- Over-smoothing: If the model's kernel is too smooth, it may fail to capture important, sharp variations in the response surface [23].
- Inadequate Acquisition Maximization: If the acquisition function is not maximized effectively, the algorithm may not select the most informative next experiment [23].
- High-Dimensional Search Spaces: BO's performance can degrade in very high-dimensional spaces (e.g., when incorporating excessive expert knowledge through many features), as the complexity increases dramatically [66] [12].
- Noisy Data with Low Effect Sizes: In applications with high noise relative to the effect size (common in biological systems), standard BO can over-sample boundaries and fail to converge. Using noise-robust models and boundary-avoiding techniques can mitigate this [67].
Q3: Can Bayesian Optimization handle multiple objectives simultaneously, such as maximizing yield while minimizing cost? Yes, through Multi-Objective Bayesian Optimization (MOBO). Instead of seeking a single best solution, MOBO identifies a set of Pareto-optimal solutions representing the best possible trade-offs between conflicting objectives [16]. Frameworks like TSEMO (Thompson Sampling Efficient Multi-Objective) have been successfully applied to chemical synthesis to find such Pareto frontiers [16].
Q4: How do I incorporate my domain expertise and existing data into a Bayesian Optimization workflow? Existing historical data can be used to pre-train the initial surrogate model, giving the algorithm a head start [66]. Furthermore, emerging frameworks like "Reasoning BO" integrate Large Language Models (LLMs) to incorporate domain knowledge, scientific hypotheses, and constraints expressed in natural language directly into the optimization loop [4]. However, caution is needed, as adding irrelevant expert knowledge via excessive features can complicate the problem and impair performance [66].
Troubleshooting Guides
Problem: Slow Convergence or Suboptimal Performance in High-Dimensional Spaces
- Potential Cause: The "curse of dimensionality." The volume of the search space grows exponentially with the number of dimensions, making it difficult for the model to learn efficiently [12] [2].
- Solution:
- Feature Adaptation: Implement frameworks like Feature Adaptive Bayesian Optimization (FABO) that dynamically identify and use the most informative features during the optimization cycles, reducing effective dimensionality [2].
- Alternative Surrogate Models: Consider using Random Forests with uncertainty estimates, which can handle higher dimensions more efficiently than standard Gaussian Processes in some cases [12].
Problem: Algorithm Suggests Impractical or Chemically Unviable Experiments
- Potential Cause: Standard BO treats the problem as a pure black box and may lack awareness of fundamental chemical constraints [12].
- Solution:
- Constraint Handling: Use Constrained Bayesian Optimization, which models the probability of constraint satisfaction (e.g., chemical stability) and incorporates it into the acquisition function [4] [12].
- Knowledge Integration: Leverage platforms or methods that allow for the incorporation of domain rules. "Reasoning BO" can use LLMs to filter out suggestions that violate known chemical principles [4].
Problem: Excessive Sampling at the Boundaries of the Parameter Space
- Potential Cause: In high-noise or low-effect-size scenarios, the model uncertainty can be disproportionately high at the edges of the explored space, leading the acquisition function to over-explore these regions [67].
- Solution: Employ a boundary-avoiding kernel or an input-warping technique within the Gaussian Process to dampen the variance estimates at the boundaries, encouraging more sampling in the interior of the space [67].
Method Comparison & Benchmarking
The table below summarizes the key characteristics of different optimization methods to aid in selection.
| Method | Core Principle | Key Strengths | Typical Application Context | Sample Efficiency |
|---|---|---|---|---|
| Bayesian Optimization (BO) | Sequential model-based optimization; uses a surrogate model (e.g., Gaussian Process) and an acquisition function to balance exploration and exploitation [32] [26]. | High sample efficiency; effective for black-box, noisy functions; theoretical foundation for uncertainty quantification [32] [16]. | Optimizing complex chemical reactions, bioprocesses, and hyperparameter tuning where experiments are costly [32] [16]. | High [16] |
| Design of Experiments (DoE) | Statistical approach using pre-defined experimental designs (e.g., factorial, central composite) to fit a response surface model [32] [65]. | Well-established, interpretable models; excellent for screening variables and understanding factor interactions in relatively simple systems [32] [65]. | Initial process development, factor screening, and optimization when a polynomial model is a good approximation [32] [65]. | Medium |
| Genetic Algorithms (GA) | Population-based metaheuristic inspired by natural selection; uses operators like crossover, mutation, and selection on a set of candidate solutions [65]. | Robust for highly non-linear, discontinuous problems; does not require derivative information; good for large search spaces [65]. | Non-model-based optimization of bioprocesses with many variables and complex interactions [65]. | Low to Medium |
| Simplex Method | A local search method that moves a geometric shape (simplex) through the parameter space based on objective function evaluations at its vertices [16]. | Simple to implement; fast convergence to a local optimum in continuous domains [16]. | Local refinement of reaction parameters when a good starting point is known [16]. | Low (for local opt.) |
Experimental Protocols for Benchmarking
Protocol 1: Benchmarking BO vs. DoE for a Chemical Reaction
- Objective: Maximize reaction yield by optimizing parameters like temperature, residence time, and catalyst concentration.
- BO Workflow:
- Initialization: Select a small set of initial points (e.g., via Latin Hypercube Sampling) to build the initial surrogate model.
- Surrogate Model: Choose a Gaussian Process with a Matern 5/2 kernel to model the yield response surface [32].
- Acquisition Function: Use Expected Improvement (EI) to propose the next experiment [16] [26].
- Iteration: Run the proposed experiment, obtain the yield, and update the GP model. Repeat for a fixed number of iterations or until convergence.
- DoE Workflow:
- Evaluation: Compare the number of experiments required by each method to reach a yield within 5% of the maximum achievable yield found.
Protocol 2: Benchmarking BO vs. GA for a Multi-Objective Bioprocess Problem
- Objective: Optimize a fermentation process to maximize product titer while minimizing impurity formation (a two-objective problem).
- BO Workflow (MOBO):
- Setup: Use a framework like TSEMO, which employs Thompson sampling and an internal genetic algorithm (NSGA-II) to optimize the acquisition function for multiple objectives [16].
- Modeling: Use independent Gaussian Processes for each objective.
- Output: The algorithm returns an approximated Pareto front after a set number of experiments.
- GA Workflow:
- Initialization: Create an initial population of candidate parameter sets.
- Evaluation: Run experiments for the entire population and measure both titer and impurity.
- Selection & Evolution: Use a multi-objective selection method (e.g., NSGA-II) to select parents and create a new generation via crossover and mutation [65].
- Output: The final population's non-dominated solutions form the Pareto front.
- Evaluation: Compare the hypervolume of the Pareto front obtained by each method after an equal number of experimental evaluations.
Research Reagent Solutions
The table below lists key computational tools and their functions for implementing these optimization methods.
| Item Name | Function in Experiment | Key Feature / Use Case |
|---|---|---|
| Gaussian Process (GP) | Serves as a probabilistic surrogate model in BO, predicting the objective function and quantifying uncertainty [32] [26]. | The default model for most BO applications due to its strong uncertainty quantification. Ideal for problems with continuous parameters and low-to-medium dimensionality [32]. |
| Random Forest (RF) with Uncertainty | An alternative surrogate model for BO (e.g., used in Citrine's platform) [12]. | Better scalability for higher-dimensional problems and offers built-in feature importance for interpretability [12]. |
| Thompson Sampling Efficient Multi-Objective (TSEMO) | An acquisition function algorithm for Multi-Objective BO (MOBO) [16]. | Efficiently explores the Pareto front in multi-objective chemical reaction optimization problems [16]. |
| Feature Adaptive BO (FABO) | A framework that dynamically adapts material or molecular representations during BO cycles [2]. | Essential for optimizing complex materials (e.g., MOFs) where the relevant features are not known in advance [2]. |
| Boundary-Avoiding Kernel | A specialized kernel for Gaussian Processes that mitigates over-sampling at parameter space boundaries [67]. | Crucial for applications with high noise and low effect sizes, such as in neuromodulation and some bioprocesses [67]. |
Optimization Workflow Diagram
The following diagram illustrates a standard Bayesian Optimization cycle, highlighting its iterative, model-based nature.
Frequently Asked Questions
What are the primary quantitative metrics for evaluating Bayesian Optimization (BO) performance in chemical tasks? The key metrics for evaluating BO performance are the Best Observed Value (e.g., highest yield or selectivity), Optimization Efficiency (the number of experiments required to find the optimum), and Convergence Rate (how quickly the algorithm approaches the best value). For multi-objective problems, the Hypervolume Indicator of the Pareto front is a crucial metric for assessing the trade-offs between different objectives [62].
Our BO campaign seems to have stalled in a local optimum. How can we diagnose and fix this? This is a common failure mode. Stalling can be diagnosed by monitoring the acquisition function values and the lack of improvement in the best observed value over several iterations. Mitigations include adjusting the acquisition function to favor more exploration, incorporating domain knowledge via a knowledge graph to guide the search away from implausible regions, or using a hybrid framework that combines BO with global heuristics from Large Language Models (LLMs) [4] [67].
Why does my BO model perform poorly when we have a large number of material features? High-dimensional feature spaces are a known challenge for BO, often leading to poor performance due to the "curse of dimensionality." This can be addressed by integrating dynamic feature selection directly into the BO loop. The Feature Adaptive Bayesian Optimization (FABO) framework, for example, uses methods like Maximum Relevancy Minimum Redundancy (mRMR) at each cycle to identify and use only the most informative features for the task [2].
How can we effectively use BO for tasks with multiple, conflicting objectives, like maximizing yield while minimizing cost? For multi-objective Bayesian optimization (MOBO), the goal is to find a set of Pareto-optimal solutions. Success is measured by the quality of the Pareto front, typically using the Hypervolume Indicator. This metric calculates the volume in objective space that is dominated by the discovered solutions, providing a single scalar to compare the performance of different optimization runs [16] [62].
How do we handle the high noise levels typical of chemical experiments in BO? Standard BO can be sensitive to high noise levels. Robustness can be improved by using noise-aware surrogate models and specialized kernels. For instance, research in neuromodulation (which faces similar noise challenges) found that using an Iterated Brownian-bridge kernel combined with input warping significantly improved performance for low signal-to-noise ratio tasks [67].
Troubleshooting Guides
Problem: Slow or Inefficient Convergence
Diagnosis:
- The algorithm requires an excessive number of experiments to find a satisfactory solution.
- The best-found value plateaus well before the budget is exhausted.
Solutions:
- Improve Initial Sampling: Ensure the initial set of experiments (e.g., via Sobol sequences) provides good coverage of the search space [62].
- Incorporate Prior Knowledge: Use a framework like Reasoning BO to inject chemical domain knowledge or literature-derived rules. This can guide the algorithm toward promising regions faster and away from scientifically implausible ones [4].
- Adapt the Representation: For material design tasks, implement a feature-adaptive method like FABO to dynamically refine the feature set, reducing dimensionality and focusing on relevant parameters [2].
Problem: Algorithm Over-explores Boundary Regions
Diagnosis:
- The algorithm suggests experiments at the extreme edges of the parameter space, which are often impractical or unsafe.
- This is a documented failure mode in problems with low effect sizes, where uncertainty at the boundaries becomes disproportionately high [67].
Solutions:
- Apply a Boundary-Avoiding Kernel: Use a specialized kernel like the Iterated Brownian-bridge kernel that actively discourages sampling near the predefined boundaries of the search space [67].
- Define Explicit Constraints: Formulate the problem using Constrained Bayesian Optimization, where parameter limits or other expensive-to-evaluate constraints are directly modeled to restrict the search to a feasible region [62].
Problem: Handling Categorical Parameters (e.g., Solvent or Catalyst Type)
Diagnosis:
- Standard Gaussian Process models, which use continuous kernels, struggle to handle non-numeric parameters effectively.
Solutions:
- Use Specialized Kernels: Implement kernels designed for mixed spaces, which can handle both continuous (e.g., temperature, concentration) and categorical (e.g., solvent identity) parameters.
- Leverage Expert LLMs: Frameworks like Reasoning BO can leverage LLMs to reason about categorical choices based on chemical knowledge, assigning confidence scores to different catalysts or solvents before expensive lab experiments are conducted [4].
Performance Metrics and Experimental Protocols
The following table summarizes the core metrics used to evaluate the success of a Bayesian Optimization campaign in chemical applications.
Table 1: Key Performance Metrics for Bayesian Optimization
| Metric | Description | Application Context |
|---|---|---|
| Best Observed Value | The optimal value of the objective function (e.g., yield, selectivity) found during the optimization. | Single-objective optimization; the primary metric for most yield-maximization tasks [4]. |
| Simple Regret | The difference between the optimal value and the best value found by the algorithm. | Measures the cost of not knowing the optimum beforehand; lower values indicate better performance. |
| Convergence Curve | A plot of the best observed value against the number of experiments. | Visualizes optimization efficiency and speed; a steeper curve indicates faster convergence [4]. |
| Hypervolume Indicator | The volume of the objective space dominated by the Pareto front, relative to a reference point. | Multi-objective optimization (MOBO); a larger hypervolume indicates a better approximation of the true Pareto front [16] [62]. |
| Number of Experiments | The total number of experiments required to meet a pre-defined performance threshold. | Measures sample efficiency; critical when experiments are expensive or time-consuming [62]. |
Experimental Protocol: Benchmarking BO Performance
This protocol outlines a standard method for comparing the performance of different BO algorithms or configurations on a chemical task, as demonstrated in various studies [4] [16].
Define the Optimization Problem:
- Objective: Clearly define the primary objective (e.g., "maximize reaction yield").
- Parameters: Specify all tunable continuous (temperature, time) and categorical (catalyst, solvent) parameters and their ranges.
- Constraints: Identify any hard constraints (e.g., "temperature must be below solvent boiling point").
Establish Baseline Performance:
- Run a baseline method, such as a random search or one-factor-at-a-time (OFAT), for a fixed number of experiments (e.g., 50 runs).
- Record the convergence curve and the best observed value.
Execute Bayesian Optimization:
- Initial Sampling: Start the BO campaign with an initial set of points (e.g., 5-10), typically generated via a space-filling design like Sobol sequences [62].
- Main Loop: For a fixed number of iterations (e.g., 40-50), run the BO cycle:
- Fit the surrogate model (e.g., Gaussian Process) to all collected data.
- Use the acquisition function (e.g., Expected Improvement) to select the next experiment.
- (Simulate) running the experiment and recording the result.
- Record the sequence of suggestions and outcomes.
Analyze and Compare Results:
- For each method (baseline and BO), plot the convergence curve.
- Compare the final Best Observed Value and the number of experiments needed to reach 95% of that value.
- If it's a multi-objective problem, calculate and compare the Hypervolume Indicator of the resulting Pareto fronts.
The diagram below illustrates the core BO workflow and where key metrics are evaluated within the cycle.
BO Workflow and Evaluation
The Scientist's Toolkit: Essential Materials and Representations
For a successful BO campaign in chemical synthesis, careful preparation of the "research reagents"—the data, representations, and algorithms—is crucial.
Table 2: Essential Components for a Chemical BO Campaign
| Item | Function | Example/Note |
|---|---|---|
| High-Dimensional Feature Pool | A comprehensive numerical representation of the chemical search space. | Includes chemical (e.g., RACs, stoichiometry) and geometric (e.g., pore size) descriptors for materials [2]. |
| Surrogate Model | A probabilistic model that approximates the expensive-to-evaluate objective function. | Gaussian Process (GP) is the most common, providing predictions with uncertainty estimates [16] [62]. |
| Acquisition Function | A utility function that guides the selection of the next experiment by balancing exploration and exploitation. | Expected Improvement (EI) and Upper Confidence Bound (UCB) are popular choices [16] [62]. |
| Domain Knowledge Base | Structured or unstructured knowledge (e.g., reaction rules, safety constraints) to guide and validate suggestions. | Implemented via knowledge graphs or vector databases in frameworks like Reasoning BO [4]. |
| Feature Selection Method | An algorithm to dynamically identify the most relevant features during optimization. | Maximum Relevancy Minimum Redundancy (mRMR) or Spearman Ranking can be used in the FABO framework [2]. |
Advanced Workflow: Integrating Adaptive Feature Selection
For complex material discovery tasks, selecting the right features is paramount. The Feature Adaptive Bayesian Optimization (FABO) framework integrates this step directly into the BO loop. The following diagram outlines this advanced workflow.
Adaptive Feature Selection Workflow
This technical support center is designed for researchers and scientists employing Bayesian optimization (BO) in pharmaceutical development. BO is a machine learning strategy for globally optimizing expensive black-box functions, making it ideal for resource-intensive tasks like chemical synthesis optimization and hyperparameter tuning in drug discovery [16] [68]. This guide provides targeted troubleshooting for common experimental challenges.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
FAQ 1: My Bayesian optimization algorithm seems trapped in a local optimum. How can I improve its exploration?
- Problem: The optimization process is yielding suboptimal results, likely due to an imbalance between exploitation (refining known good areas) and exploration (testing new regions).
- Solution & Protocol: Implement an adaptive representation framework or adjust the acquisition function.
- Diagnosis: Check if your surrogate model's predictions have become over-confident in a small region, indicated by low uncertainty estimates across most of the search space.
- Recommended Action: Switch from an exploitative acquisition function like Expected Improvement (EI) to a more exploratory one like Upper Confidence Bound (UCB) by increasing its
kappaparameter [2] [16]. For complex material design, consider the Feature Adaptive Bayesian Optimization (FABO) framework, which dynamically identifies the most relevant molecular features during the optimization cycle, preventing the search from being biased by an initially poor representation [2].
FAQ 2: I need to optimize for multiple, conflicting objectives (e.g., high yield and low cost). How can BO handle this?
- Problem: Single-objective BO is insufficient for real-world scenarios requiring a balance between multiple targets.
- Solution & Protocol: Employ Multi-Objective Bayesian Optimization (MOBO) to identify a Pareto front.
- Diagnosis: Confirm that your objectives are indeed conflicting. Plotting initial data points should show no clear single winner.
- Recommended Action: Use a MOBO framework like
TSEMO(Thompson Sampling Efficient Multi-Objective). The workflow involves building a Gaussian Process surrogate model for each objective and using an acquisition function likeq-NEHVIto guide experiments toward the Pareto frontier, representing optimal trade-offs [16]. The following table summarizes a protocol based on a successful MOBO application in chemical synthesis [16]:
Table 1: Experimental Protocol for Multi-Objective Optimization of a Chemical Reaction
| Step | Action | Details & Parameters |
|---|---|---|
| 1 | Define Variables & Objectives | Variables: Temperature, residence time, concentration.Objectives: Maximize Space-Time Yield (STY), Minimize E-Factor (environmental impact). |
| 2 | Initial Experimental Design | Perform a small set (e.g., 10-15) of initial experiments using a space-filling design (e.g., Latin Hypercube) to gather baseline data. |
| 3 | Configure MOBO | Surrogate Model: Gaussian Process with Matern kernel.Acquisition Function: Thompson Sampling Efficient Multi-Objective (TSEMO). |
| 4 | Iterative Optimization Loop | For each iteration (e.g., 50-80 runs): a. Update GP models with all collected data. b. Use TSEMO to select the next experiment(s). c. Run the experiment and record STY and E-Factor. |
| 5 | Analysis | Identify the final Pareto front from the collected data to visualize the best possible trade-offs between the objectives. |
The workflow for this multi-objective optimization is outlined below.
FAQ 3: My experimental evaluations are expensive and slow. How can I minimize the number of experiments needed?
- Problem: The high cost of each experiment (e.g., chemical synthesis, biological assay) severely limits the budget for the optimization campaign.
- Solution & Protocol: Leverage BO's sample efficiency by using a proper surrogate model and acquisition function, potentially integrating prior knowledge.
- Diagnosis: Compare your BO performance against a random search baseline; a well-tuned BO should find better solutions in fewer evaluations [2] [69].
- Recommended Action:
- Ensure your Gaussian Process surrogate model uses an appropriate kernel (e.g., Matern kernel for chemical spaces) [70].
- Use an acquisition function like Expected Improvement (EI), which is designed to find the global optimum with fewer queries than grid or random search [16] [70].
- For novel tasks with no prior data, start with a comprehensive feature set and let a framework like FABO dynamically reduce dimensionality [2]. If domain knowledge exists (e.g., from literature), use frameworks like Reasoning BO to incorporate these insights, significantly accelerating the initial search [4].
Table 2: Efficiency Comparison of Optimization Methods
| Optimization Method | Relative Number of Experiments | Best Use Case |
|---|---|---|
| Grid Search | High (~100+ in example) [70] | Very low-dimensional spaces only |
| Random Search | Medium | Better than grid search for higher dimensions [71] |
| Traditional DoE | Medium-High | Building initial models when data is scarce |
| Bayesian Optimization | Low (e.g., ~10 for formulation) [69] | Expensive, black-box function optimization |
FAQ 4: How can I incorporate my scientific knowledge into the BO process to make it more reliable?
- Problem: Standard BO treats the objective as a pure black box, ignoring valuable expert knowledge and sometimes suggesting implausible experiments.
- Solution & Protocol: Implement a knowledge-guided BO framework.
- Diagnosis: The algorithm is suggesting parameter combinations that violate known chemical rules or synthetic constraints.
- Recommended Action: Adopt the "Reasoning BO" framework [4]. This integrates a large language model (LLM) into the BO loop. The LLM evaluates candidate points proposed by the BO based on domain knowledge (e.g., chemical reaction rules, safety constraints), generates scientific hypotheses, and filters out implausible suggestions. This creates a more trustworthy and efficient optimization process.
The Scientist's Toolkit: Essential Research Reagents & Materials
Table 3: Key Reagent Solutions for Bayesian-Optimized Chemical Synthesis
| Item | Function in Optimization | Example & Notes |
|---|---|---|
| Solvent Library | Categorical variable for reaction medium optimization. | A diverse library (e.g., polar protic, polar aprotic, non-polar) is crucial for screening and understanding solvent effects [16]. |
| Catalyst Library | Categorical variable for screening reaction activity & selectivity. | Includes varying metal centers (e.g., Pd, Cu, Ni) and ligand structures (e.g., phosphines, amines) [16]. |
| Chemical Building Blocks | Core components for constructing diverse molecular libraries. | Used in click chemistry (e.g., azides, alkynes) for rapid, modular assembly of compounds for screening [72]. |
| DNA-Encoded Library (DEL) | Technology for ultra-high-throughput screening of millions of compounds. | Each small molecule is tagged with a unique DNA barcode, enabling efficient selection against biological targets [72]. |
| PROTAC Molecules | Key reagents for Targeted Protein Degradation (TPD). | Bifunctional molecules that recruit cellular machinery to degrade disease-causing proteins; often assembled using click chemistry [72]. |
Frequently Asked Questions (FAQs)
FAQ: What are the proven success rates of autonomous laboratories in discovering new materials? The A-Lab, an autonomous laboratory for solid-state synthesis, successfully realized 41 out of 58 target novel compounds in continuous operation. This demonstrates a 71% success rate in discovering and synthesizing new, computationally predicted inorganic materials, spanning a variety of oxides and phosphates [73].
FAQ: Can AI-driven optimization really outperform human experts in chemical reaction optimization?
Yes. In multiple validated cases, autonomous systems have matched or surpassed human performance. The RoboChem system, for instance, matched or improved upon yields reported in previously published research papers in 80% of cases it attempted to replicate [74]. Furthermore, in a specific Direct Arylation chemical reaction task, an AI-enhanced method achieved a final yield of 94.39%, significantly higher than the 76.60% obtained through traditional Bayesian optimization [4].
FAQ: How efficiently can these systems operate compared to traditional research?
Autonomous labs can drastically accelerate discovery timelines. The A-Lab conducted its discovery campaign over just 17 days of continuous operation [73]. Similarly, the RoboChem system can optimize the synthesis of about ten to twenty molecules in a week—a task that would typically take a PhD student several months [74]. In a pharmaceutical process development setting, one ML-driven workflow identified improved process conditions at scale in just 4 weeks, compared to a previous 6-month development campaign [1].
FAQ: What is the role of Bayesian optimization in these self-driving labs? Bayesian Optimization (BO) is a core AI component for experimental planning in self-driving labs. It uses probabilistic surrogate models and acquisition functions to autonomously decide which experiment to perform next by balancing the exploration of unknown conditions with the exploitation of known promising areas [2] [16]. This allows for the efficient optimization of complex, multi-variable experiments with minimal manual intervention.
FAQ: My Bayesian optimization seems to be getting stuck in local optima. What can I do? A common challenge with traditional BO is its susceptibility to local optima [4]. To address this, you can:
- Integrate Large Language Models (LLMs): Frameworks like "Reasoning BO" use the global heuristic perspective and cross-domain knowledge of LLMs to help guide the search away from local optima and generate scientifically plausible hypotheses for exploration [4].
- Adapt Feature Representations: Using a framework like Feature Adaptive Bayesian Optimization (FABO) can dynamically identify the most informative features during the optimization process, which can lead to a more efficient search and better performance, especially in novel tasks [2].
- Utilize Multi-fidelity Modeling: If you have access to data of varying cost and accuracy (e.g., computational simulations vs. real experiments), multi-fidelity Bayesian optimization can help navigate the search space more efficiently by leveraging cheaper, lower-fidelity data to guide experiments [52].
Troubleshooting Guides
Issue: Poor Performance in High-Dimensional Search Spaces
Symptoms
- The optimization algorithm fails to find improved conditions even after many experimental cycles.
- Performance is worse than a simple random search baseline.
Solutions
- Implement Dynamic Feature Selection: Integrate a method like Feature Adaptive Bayesian Optimization (FABO). FABO starts with a full set of features but dynamically selects the most relevant ones at each cycle using methods like mRMR (Maximum Relevancy Minimum Redundancy), preventing the "curse of dimensionality" and improving efficiency [2].
- Use Scalable Representations: For molecular design, ensure your initial feature set is both complete and compact. For molecules, consider using graph-based representations or Revised Autocorrelation Calculations (RACs) that effectively capture chemical nature [2].
- Leverage Domain Knowledge: Guide the algorithm by incorporating chemical intuition, either by defining a plausible discrete combinatorial set of reaction conditions at the start [1] or by using an LLM to inject domain priors through natural language [4].
Resolution Workflow
Issue: Failure to Synthesize Target Material in an Autonomous Lab
Symptoms
- X-ray diffraction (XRD) analysis shows low or zero yield of the target material.
- The autonomous system fails to identify a viable synthesis recipe.
Solutions
- Check for Slow Reaction Kinetics: This is the most common failure mode. Analyze if reaction steps have low driving forces (<50 meV per atom). The system should propose follow-up recipes with higher temperatures or longer reaction times [73].
- Review Precursor Selection: The choice of precursor is critical. Use the lab's active learning cycle to propose alternative precursor sets that avoid intermediates with a small driving force to form the target. The A-Lab's ARROWS3 algorithm uses a database of observed pairwise reactions and thermodynamic data to prioritize such pathways [73].
- Verify Computational Data: In some cases, the initial computational data predicting the material's stability may be inaccurate. Re-evaluate the target's stability using improved ab initio calculations [73].
Resolution Workflow
Issue: Inefficient Multi-Objective Optimization with Large Batch Sizes
Symptoms
- The optimization process is computationally slow when handling multiple objectives (e.g., yield and selectivity) in large batches (e.g., a 96-well plate).
- The algorithm fails to identify a diverse and high-performing Pareto front.
Solutions
- Choose Scalable Acquisition Functions: Avoid acquisition functions with exponential computational complexity. Instead, use scalable functions like q-NParEgo, Thompson Sampling with Hypervolume Improvement (TS-HVI), or q-Noisy Expected Hypervolume Improvement (q-NEHVI) which are designed for large batch sizes [1].
- Start with Smart Initialization: Begin the optimization campaign with algorithmic quasi-random Sobol sampling to maximize the initial coverage of the reaction space, increasing the chance of discovering informative regions [1].
- Emulate Virtual Benchmarks: To test and tune your optimization pipeline before running costly real experiments, train machine learning regressors on existing datasets to create large-scale virtual benchmarks. This allows for performance evaluation using metrics like hypervolume [1].
Experimental Protocols & Data
Table 1: Quantitative Performance of Autonomous Discovery Platforms
| Platform / System Name | Domain | Key Performance Metric | Result | Reference |
|---|---|---|---|---|
| The A-Lab | Solid-state materials synthesis | Success rate (novel compounds) | 41/58 targets (71%) | [73] |
| RoboChem | Organic photocatalysis | Replication success of literature results | ~80% of cases (matched or improved yield) | [74] |
| Reasoning BO | Chemical reaction yield | Final yield in Direct Arylation reaction | 94.39% (vs. 76.60% for standard BO) | [4] |
| Minerva | Pharmaceutical process development | Timeline acceleration | 4 weeks vs. 6 months | [1] |
Table 2: Key Research Reagent Solutions in Autonomous Discovery
| Reagent / Material | Function in the Experiment | Example Use Case |
|---|---|---|
| Precursor Powders | Starting materials for solid-state synthesis. Their selection is critical for reaction pathway and success. | Synthesis of novel inorganic compounds in the A-Lab [73]. |
| Photocatalysts | Absorb light to initiate molecular transformations in photochemical reactions. | RoboChem uses them for photocatalysis, with the AI finding optimal activation conditions [74]. |
| Solvents & Ligands | Create the chemical environment for reactions; significantly influence yield and selectivity. | Categorical variables optimized in HTE campaigns for Suzuki and Buchwald-Hartwig reactions [1]. |
| Revised Autocorrelation Calculations (RACs) | Numerical descriptors that capture the chemical nature of molecules and materials for the ML model. | Used as part of the feature set for representing Metal-Organic Frameworks (MOFs) in Bayesian optimization [2]. |
Bayesian Optimization (BO) is a powerful, sample-efficient strategy for optimizing black-box functions, making it highly valuable for expensive and time-consuming experiments in chemical and pharmaceutical development. Its application ranges from drug formulation and molecular design to process parameter tuning [75] [76]. However, its effectiveness is bounded by specific problem characteristics. When these boundaries are crossed, BO can underperform, sometimes even being outperformed by traditional methods like Design of Experiments (DoE) or expert intuition [66]. This guide outlines key limitations and provides troubleshooting advice to help researchers diagnose and address these challenges in their chemical hyperparameter tuning projects.
FAQ: Common Challenges in Bayesian Optimization
Q1: Why does my Bayesian Optimization converge to a poor local solution, even though it is designed for global optimization?
BO can get trapped in local optima, particularly when the acquisition function over-prioritizes exploitation (refining known good areas) over exploration (investigating uncertain regions) [4]. This sensitivity to initial sampling can cause the algorithm to miss the global optimum, especially in complex, multi-modal search spaces common in chemical property landscapes [4] [77].
Q2: My BO algorithm is performing worse than a human expert's Design of Experiments. What could be going wrong?
This is a documented failure mode. A primary cause is the incorporation of incorrect or mis-specified prior knowledge. In a real-world case involving plastic compound development, adding expert knowledge via numerous material data-sheet features transformed the problem into a high-dimensional one, complicating the surrogate model's task and impairing BO's performance. Simplifying the problem formulation by using only the core mixture proportions resolved the issue [66].
Q3: How should I handle failed or invalid experiments in my autonomous optimization loop?
Unknown constraints—where an experiment fails and provides no objective function value (e.g., a failed synthesis or unstable material)—are a major challenge [78]. Standard BO treats these failures as uninformative. To address this, use feasibility-aware BO frameworks like Anubis, which employ a variational Gaussian process classifier to model the probability of constraint violation on-the-fly. This allows the acquisition function to balance finding high-performance points with avoiding likely-infeasible regions [78].
Q4: Can I use BO for optimizing systems with a large number of parameters (high-dimensional spaces)?
BO's performance generally degrades in high-dimensional spaces (e.g., >20 parameters)—a phenomenon known as the "curse of dimensionality." The volume of the search space grows exponentially, making it difficult for the surrogate model to learn the objective function's structure. While recent methods like LLM-guided BO try to mitigate this by injecting procedural knowledge [79] [4], high dimensionality remains a fundamental challenge for standard BO.
Troubleshooting Guide: Identifying and Solving BO Problems
This section provides a structured workflow to diagnose common BO failures in chemical research, based on the analysis of real-world cases [66] [78].
Diagram: Diagnostic workflow for BO performance issues. Follow the path based on your specific problem to identify potential solutions.
Scenario 1: BO Performance is Worse Than Expert DoE
- Problem: The algorithm fails to find a satisfactory solution compared to traditional methods.
- Underlying Cause: Often stems from an over-complicated problem formulation. Adding excessive expert knowledge through many input features can create a high-dimensional problem that obscures the true optimum [66].
- Solution:
- Simplify the Model: Re-formulate the problem using the most fundamental parameters. In a plastic compounding case, reducing the model to just the four core mixture components (virgin plastic, recycled plastic, filler, impact modifier) resolved the performance issue [66].
- Validate Expert Features: Critically assess whether each piece of incorporated knowledge directly relates to the optimization objective. Avoid using features that are only peripherally related.
- Problem: The algorithm repeatedly suggests experimental conditions that fail (e.g., failed syntheses, unstable materials) [78].
- Underlying Cause: The presence of a priori unknown constraints is not being accounted for. Standard BO has no mechanism to learn from failure.
- Solution:
- Adopt Feasibility-Aware BO: Implement an algorithm like Anubis that uses a dual-surrogate model approach [78].
- Model the Constraint: Use a classifier (e.g., a Gaussian process classifier) to model the probability that a given set of parameters will lead to a valid experiment. This model is updated with each success or failure.
- Use a Modified Acquisition Function: Employ acquisition functions such as Expected Constrained Improvement that balance objective improvement with the predicted probability of feasibility [78].
Scenario 3: BO Gets Stuck in a Local Optimum
- Problem: The optimization process plateaus at a sub-optimal solution.
- Underlying Cause: The acquisition function's balance between exploration and exploitation is skewed, or the initial samples were not representative of the global search space.
- Solution:
- Adjust the Acquisition Function: Favor more exploratory acquisition functions, such as those with a higher weight on Upper Confidence Bound (UCB), especially in early stages [77].
- Increase Initial Sampling: Ensure the initial set of random samples (the "initial design") is large and diverse enough to help the surrogate model build a reasonable initial picture of the objective landscape [77].
- Incorporate Global Heuristics: Leverage LLM-guided frameworks like Reasoning BO, which can use cross-domain knowledge to propose global heuristic steps, helping to jump out of local optima [4].
Decision Framework: When to Use (or Avoid) Bayesian Optimization
The table below summarizes key limitation scenarios and alternative approaches to consider.
| Limitation Scenario | Key Indicators | Recommended Alternative Actions |
|---|---|---|
| High-Dimensional Problems (>15-20 parameters) [66] [41] | Slow progress, surrogate model with high uncertainty everywhere, performance worse than random search. | Use dimensionality reduction (e.g., PCA), switch to algorithms like Random Forest or TPE for HPO [77], or employ LLMs to guide the search in a reduced space [4]. |
| Presence of Unknown Constraints [78] | A high rate of experimental failures (e.g., failed syntheses) that provide no usable data. | Implement a feasibility-aware BO method (e.g., Anubis) [78] that actively learns and avoids regions of constraint violation. |
| Mis-specified or Unhelpful Prior Knowledge [66] | Performance degrades after incorporating expert knowledge or features. BO is outperformed by simpler DoE. | Audit and simplify the feature set. Validate that each piece of prior knowledge is directly relevant to the objective. |
| Need for High Interpretability | The optimization process provides no scientifically meaningful insights or hypotheses. | Consider LLM-guided BO frameworks (e.g., Reasoning BO) that generate and refine scientific hypotheses [4], or use simpler, more interpretable models. |
| Very Limited Evaluation Budget (<10 evaluations) | The algorithm cannot build an accurate surrogate model with the available data. | Leverage meta-learning or MDP priors (e.g., ProfBO) that transfer knowledge from related tasks to accelerate convergence [79]. |
The Scientist's Toolkit: Key Reagents & Computational Tools
| Item / Solution | Function in Bayesian Optimization | Example Use-Case |
|---|---|---|
| Gaussian Process (GP) Regression | Serves as the surrogate model that approximates the unknown black-box function and provides uncertainty estimates [4] [77]. | Modeling the relationship between hyperparameters and model accuracy in a Graph Neural Network (GNN) for molecular property prediction [41]. |
| Expected Improvement (EI) | An acquisition function that selects the next point to evaluate by balancing the potential reward of a new sample [76] [77]. | Optimizing tablet tensile strength and disintegration time in pharmaceutical formulation to reduce experiments from 25 to 10 [76]. |
| Tree-structured Parzen Estimator (TPE) | A surrogate model alternative to GP, often more efficient for high-dimensional, categorical hyperparameters [77] [41]. | Hyperparameter optimization and neural architecture search for complex machine learning models like GNNs [41]. |
| Anubis Framework | A feasibility-aware BO package that handles unknown constraints using a Gaussian process classifier [78]. | Optimizing molecular designs where synthetic accessibility is an unknown constraint [78]. |
| Reasoning BO Framework | An LLM-guided BO that uses large language models to generate scientific hypotheses and guide the sampling process [4]. | Chemical reaction yield optimization, where it significantly outperformed traditional BO (60.7% vs 25.2% yield) [4]. |
Conclusion
Bayesian Optimization represents a paradigm shift in chemical hyperparameter tuning, offering a data-efficient and intelligent framework that systematically navigates complex experimental spaces. By synthesizing the core intents, this article establishes BO as a robust methodology that outperforms traditional trial-and-error and statistical approaches, particularly in multi-objective drug discovery and bioprocess engineering. The key takeaways highlight its ability to incorporate expert intuition, handle real-world noise, and significantly reduce the number of costly experiments. Future directions point towards the deeper integration of AI, such as with diffusion models for property prediction, the development of more robust multi-fidelity and transfer learning models, and the wider adoption of fully autonomous, self-optimizing laboratory systems. These advancements promise to further accelerate preclinical timelines, reduce development costs, and ultimately fast-track the delivery of new therapeutics to the clinic.
References
- 1. Highly parallel optimisation of chemical reactions through ... [https://www.nature.com/articles/s41467-025-61803-0]
- 2. Adaptive representation of molecules and materials in ... [https://pubs.rsc.org/en/content/articlehtml/2025/sc/d5sc00200a]
- 3. Combining Bayesian optimization and automation to ... [https://pubs.rsc.org/en/content/articlehtml/2024/sc/d3sc05607d]
- 4. Reasoning BO: Enhancing Bayesian Optimization with the ... [https://arxiv.org/html/2505.12833v2]
- 5. Accelerated Chemical Reaction Optimization Using Multi-Task ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10214532/]
- 6. Introduction to Bayesian Optimization [https://ax.dev/docs/intro-to-bo/]
- 7. Bayesian optimization for chemical products and functional ... [https://www.sciencedirect.com/science/article/abs/pii/S2211339821000605]
- 8. Bayesian Optimization in Machine Learning [https://www.geeksforgeeks.org/artificial-intelligence/bayesian-optimization-in-machine-learning/]
- 9. Exploring Bayesian Optimization [https://distill.pub/2020/bayesian-optimization]
- 10. Bayesian Optimization Algorithm - MATLAB & Simulink [https://www.mathworks.com/help/stats/bayesian-optimization-algorithm.html]
- 11. Bayesian Optimization [https://optimization.cbe.cornell.edu/index.php?title=Bayesian_Optimization]
- 12. Why Bayesian Optimization Can Fall Short for Materials ... [https://citrine.io/why-bayesian-optimization-can-fall-short-for-materials-innovation/]
- 13. Bayesian optimisation for chemical problems - RSC Publishing [https://pubs.rsc.org/en/content/articlehtml/2024/dd/d3dd00234a]
- 14. Bayesian Hyperparameter Optimization of Machine ... [https://www.mdpi.com/2076-3417/15/3/1018]
- 15. Probabilistic surrogate modeling by Gaussian process [https://www.sciencedirect.com/science/article/pii/S0951832024001947]
- 16. Bayesian Optimization for Chemical Synthesis in the Era of ... [https://www.mdpi.com/2227-9717/13/9/2687]
- 17. An introduction to surrogate modeling, Part I: fundamentals [https://towardsdatascience.com/an-introduction-to-surrogate-modeling-part-i-fundamentals-84697ce4d241/]
- 18. Introduction to Using Surrogate Models [https://www.comsol.com/support/learning-center/article/introduction-to-using-surrogate-models-94571/261]
- 19. A Visual Exploration of Gaussian Processes [https://distill.pub/2019/visual-exploration-gaussian-processes]
- 20. Acquisition functions in Bayesian Optimization [https://ekamperi.github.io/machine%20learning/2021/06/11/acquisition-functions.html]
- 21. How does Bayesian Optimization balance exploration with ... [https://stats.stackexchange.com/questions/509812/how-does-bayesian-optimization-balance-exploration-with-exploitation]
- 22. Diagnosing and fixing common problems in Bayesian ... [https://arxiv.org/html/2406.07709v1]
- 23. Diagnosing and fixing common problems in Bayesian ... [https://openreview.net/forum?id=V4aG4wsoIt]
- 24. Bayesian optimization [https://en.wikipedia.org/wiki/Bayesian_optimization]
- 25. Sequential closed-loop Bayesian optimization as a guide ... [https://www.nature.com/articles/s41557-024-01546-5]
- 26. Model: Bayesian Optimisation for Biology | Imperial - iGEM 2025 [https://2025.igem.wiki/imperial/Model]
- 27. Dynamic flow experiments for Bayesian optimization of a ... [https://pubs.rsc.org/en/content/articlehtml/2025/re/d4re00543k]
- 28. A Guide to Bayesian Optimization in Bioprocess Engineering [https://arxiv.org/html/2508.10642v1]
- 29. Application of Bayesian Optimization in HME Batch ... [https://www.sciencedirect.com/science/article/abs/pii/B978044315274050247X]
- 30. Physics-guided transfer learning for Bayesian optimization ... [https://www.sciencedirect.com/science/article/pii/S0098135425003333]
- 31. Combining Bayesian optimization and automation to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11110165/]
- 32. Bayesian Optimization in Bioprocess Engineering—Where Do ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12067035/]
- 33. Preferential Multi-Objective Bayesian Optimization for Drug ... [https://arxiv.org/html/2503.16841v1]
- 34. Recovering from errors during optimization - GitHub Pages [https://secondmind-labs.github.io/trieste/0.13.3/notebooks/recovering_from_errors.html]
- 35. Batched Bayesian Optimization for Drug Design in Noisy ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9472273/]
- 36. Troubleshooting and FAQ - Comet Docs [https://www.comet.com/docs/v2/guides/optimizer/troubleshooting-and-faq/]
- 37. Multi-objective Bayesian Optimization with Heuristic ... [https://openreview.net/forum?id=5MGL0GEaDJ]
- 38. Can AI transform the way we discover new drugs? [https://hms.harvard.edu/news/can-ai-transform-way-we-discover-new-drugs]
- 39. 2025 guide to pharmaceutical software [https://www.linkedin.com/pulse/2025-guide-pharmaceutical-software-qualiohq-wpi2e]
- 40. Exploring Regional Dynamics of Bioprocess Optimisation ... [https://www.datainsightsmarket.com/reports/bioprocess-optimisation-1441950]
- 41. Hyperparameter optimization and neural architecture ... [https://www.sciencedirect.com/science/article/pii/S0927025625002472]
- 42. The 8th Annual Bioprocessing Summit Europe 2025 [https://www.isctglobal.org/telegrafthub/blogs/ken-ip1/2025/04/09/the-8th-annual-bioprocessing-summit-europe-2025]
- 43. September 2025 [https://www.bioprocessintl.com/publications/bioprocess-international/september-2025]
- 44. Welcome to Summit's documentation! — Summit 0.8.9 ... [https://gosummit.readthedocs.io/]
- 45. Strategies — Summit 0.8.9 documentation [https://gosummit.readthedocs.io/en/latest/strategies.html]
- 46. BoTorch Tutorials [https://archive.botorch.org/v/0.1.4/tutorials/]
- 47. BoTorch Tutorials [https://botorch.org/docs/tutorials/]
- 48. Bayesian optimization with pairwise comparison data [https://botorch.org/docs/tutorials/preference_bo/]
- 49. leojklarner/gauche: A Library for Gaussian Processes in ... [https://github.com/leojklarner/gauche]
- 50. Maximizing information from chemical engineering data sets [https://www.sciencedirect.com/science/article/pii/S0009250922000537]
- 51. Are we fitting data or noise? Analysing the predictive power ... [https://pubs.rsc.org/en/content/articlelanding/2025/fd/d4fd00091a]
- 52. Multifidelity Bayesian optimization for hyperparameter ... [https://ojs.acad-pub.com/index.php/CAI/article/view/2923]
- 53. Why does Bayesian Optimization perform poorly in more than ... [https://stats.stackexchange.com/questions/564528/why-does-bayesian-optimization-perform-poorly-in-more-than-20-dimensions]
- 54. Scalable Bayesian Optimization for High-Dimensional ... [https://arxiv.org/html/2506.22533v1]
- 55. Diagnosing and fixing common problems in Bayesian ... [https://arxiv.org/abs/2406.07709]
- 56. Evolution-guided Bayesian optimization for constrained ... [https://www.nature.com/articles/s41524-024-01274-x]
- 57. Multi-objective Bayesian optimisation using q -noisy expected ... [https://pubs.rsc.org/en/content/articlehtml/2024/re/d3re00502j]
- 58. Bayesian and subset-selection methods for parameter ... [https://www.sciencedirect.com/science/article/pii/S0263876225001017]
- 59. Bayesian subset selection and variable importance for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10723825/]
- 60. Robust prior-biased acquisition function for human-in-the- ... [https://www.sciencedirect.com/science/article/pii/S0950705125000863]
- 61. Estimating expert prior knowledge from optimization ... [https://www.sciencedirect.com/science/article/pii/S0925231225008914]
- 62. Basics of Bayesian Optimization - BOA documentation [https://boa-framework.readthedocs.io/en/stable/user_guide/bo_overview.html]
- 63. Robust surrogate modeling for glass forming process [https://link.springer.com/article/10.1007/s00170-025-16123-4]
- 64. Surrogate model optimization: a comparison case study ... [https://www.sciencedirect.com/science/article/pii/S0098135425002030]
- 65. Current strategy of non-model-based bioprocess ... [https://www.sciencedirect.com/science/article/abs/pii/S0010482525005980]
- 66. A Story of Failing Bayesian Optimization Due to Additional ... [https://arxiv.org/html/2511.16230v1]
- 67. Failure modes and mitigations for Bayesian optimization of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12164532/]
- 68. Bayesian Optimization in Drug Discovery [https://pubmed.ncbi.nlm.nih.gov/37702937/]
- 69. Application of Bayesian Optimization for Pharmaceutical ... [https://link.springer.com/article/10.1007/s12247-019-09382-8]
- 70. for Efficient Bayesian Search | CodeCut Optimization Hyperparameter [https://codecut.ai/bayesian-optimization-hyperameter-search/]
- 71. in Machine Learning Using Hyperparameter ... Tuning Bayesian [https://medium.com/@linmarsirait2/hyperparameter-tuning-in-machine-learning-using-bayesian-optimization-8ee522ef6d99]
- 72. Frontiers | New strategies to enhance the efficiency and precision of... [https://www.frontiersin.org/journals/pharmacology/articles/10.3389/fphar.2025.1550158/full]
- 73. An autonomous laboratory for the accelerated synthesis of ... [https://www.nature.com/articles/s41586-023-06734-w]
- 74. Autonomous Synthesis Robot Uses AI to Speed Up ... [https://www.labmanager.com/autonomous-synthesis-robot-uses-ai-to-speed-up-chemical-discovery-31690]
- 75. Innovations in chemical process control: challenges and ... [https://www.sciencedirect.com/science/article/abs/pii/S2211339825000590]
- 76. Bayesian Thinking-5: Optimization in Pharmaceutical ... [https://www.linkedin.com/pulse/bayesian-thinking-5-optimization-pharmaceutical-development-l19zc]
- 77. Bayesian Optimization: Smarter Hyperparameter Tuning for ... [https://medium.com/@sachinsoni600517/bayesian-optimization-smarter-hyperparameter-tuning-for-machine-learning-8129534b9067]
- 78. Bayesian optimization with unknown feasibility constraints for ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00018a]
- 79. Bayesian Optimization with MDP Priors - ADS [http://adsabs.harvard.edu/abs/2025arXiv251101006L]